 Eseandre Mordi
Eseandre Mordi

⬤ Kimi.ai rolled out the Kimi K2.5 API as a production-ready model that eliminates the usual trade-off between speed and affordability. The new API hits Turbo-level speeds right out of the box—clocking in at roughly 60 to 100 tokens per second—while cutting costs significantly compared to earlier Kimi versions. It's built specifically for developers running latency-sensitive applications who can't afford to blow their budgets.
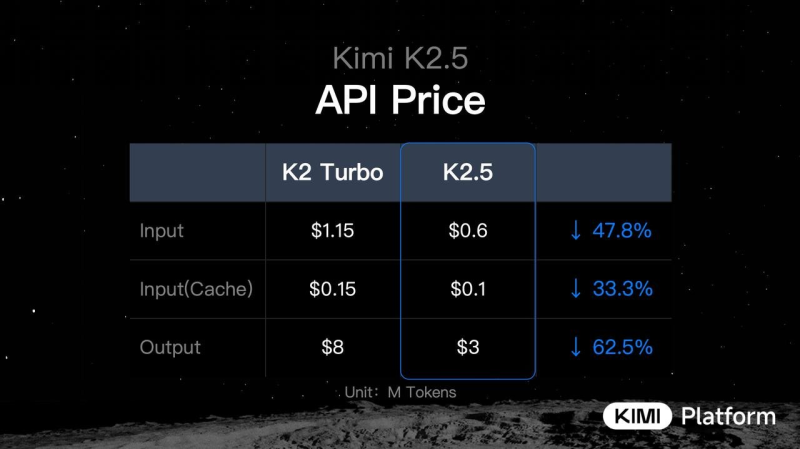
⬤ The pricing cuts are substantial across the board. Standard input tokens dropped from $1.15 to $0.60 per million tokens (47.8% cheaper than K2 Turbo), cached inputs fell from $0.15 to $0.10 per million (33.3% reduction), and output pricing saw the biggest slash—plummeting from $8 to $3 per million tokens, a 62.5% decrease. Kimi.ai points out that input costs now sit around 50% below K2 Turbo rates and roughly 20% of what Claude 4.5 Sonnet charges.
⬤ Kimi K2.5 is optimized for long-context reasoning and multi-turn agent workflows. The lower cached token pricing makes it economical for applications that reuse context repeatedly—think research assistants, autonomous agents, or complex enterprise systems that need extended conversations without lag or inflated bills.

⬤ Kimi.ai emphasizes that output quality drives real cost efficiency. K2.5 delivers higher one-shot success rates, meaning fewer retries, less prompt tweaking, and reduced inference calls overall. This quality-first approach reflects the broader market shift where AI providers compete on total operational cost rather than just raw speed, pushing the industry toward faster, cheaper, and more reliable models for actual production environments.
 Eseandre Mordi
Eseandre Mordi


