 Usman Salis
Usman Salis

AI developer platform Cursor has introduced a new methodology for evaluating large language models on agentic coding tasks. The benchmark, called CursorBench, measures both reasoning capability and token efficiency to assess how well AI systems handle multi-step coding operations - from planning and tool usage to autonomous decision-making in real developer workflows.
GPT-5.4 Leads CursorBench With 60%+ Score
The CursorBench visualization compares over 10 AI systems on two key axes: benchmark score and median token usage.
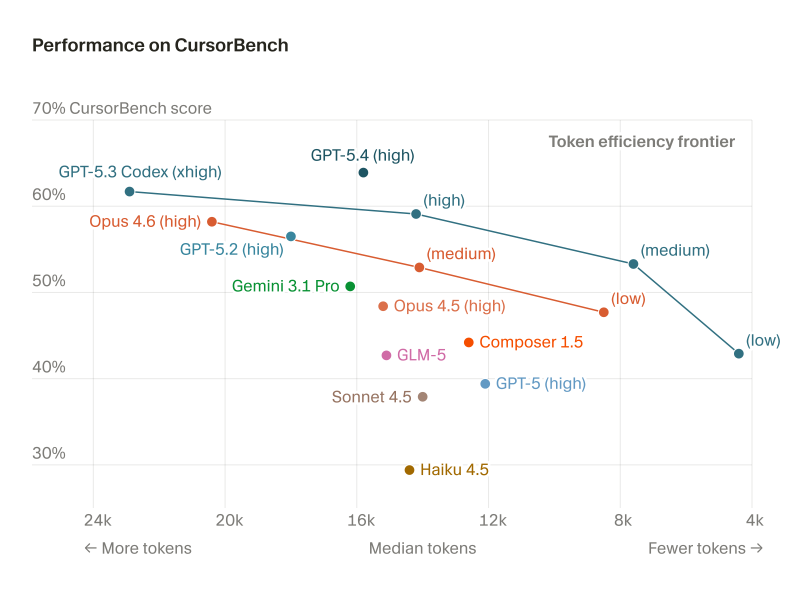
Models include GPT-5.4, GPT-5.3 Codex, GPT-5.2, Gemini 3.1 Pro, Opus 4.6, Opus 4.5, GLM-5, Sonnet 4.5, Composer 1.5, and Haiku 4.5. GPT-5.4 (high) achieves one of the strongest results, clearing 60% while maintaining mid-range token consumption.
Rather than measuring performance through traditional benchmarks, developers are increasingly focusing on real-world task execution, agent autonomy, and resource efficiency.
GPT-5.3 Codex (xhigh) also shows strong coding intelligence but sits further toward the high-token end, indicating greater computational cost. This aligns with findings from GPT-5.3 Codex Leads PinchBench With 978 Score Across 23 AI Tasks, where the model proved strong across multi-task coding benchmarks.
Token Efficiency Frontier and the Real-World AI Shift
CursorBench introduces the concept of a "token efficiency frontier" - identifying models that deliver strong performance while keeping token usage low. Some systems cut token consumption but score lower on intelligence; others push reasoning scores higher at the cost of heavier compute. That trade-off is central to evaluating coding agents for real production use. The same dynamic is visible in emerging agent frameworks like OpenClawRL 145K-Stars Framework Trains AI Agents From Live Conversations, where continuous interaction shapes agent learning over time.
The launch of CursorBench reflects a broader shift in how the AI industry defines model capability. Advances in reasoning continue to push the frontier, as shown by breakthroughs like Claude Opus 4.6 Solves Knuth's Math Problem After Weeks of Human Effort, demonstrating how top models handle complex analytical challenges. As coding agents become more embedded in software engineering, benchmarks that capture both intelligence and efficiency are becoming essential tools for understanding real-world model performance.
 Usman Salis
Usman Salis


