 Eseandre Mordi
Eseandre Mordi
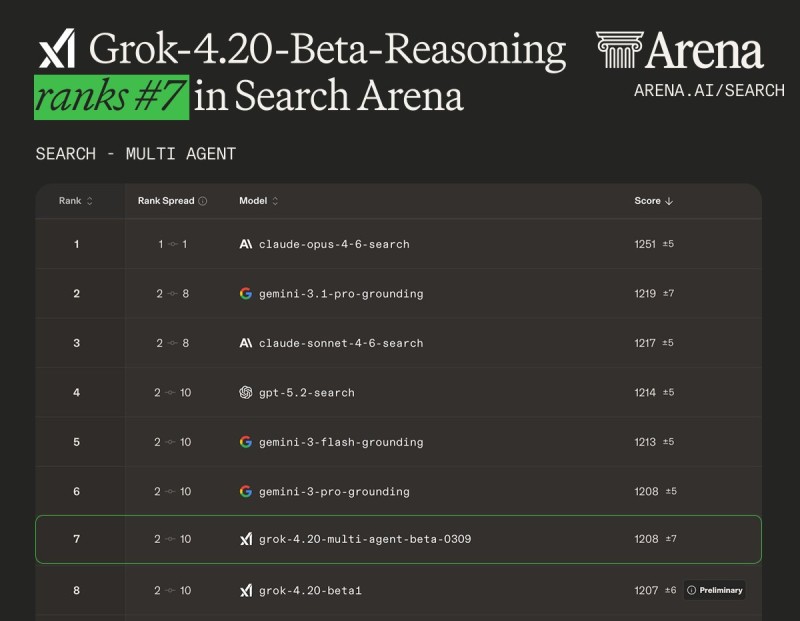
Grok 4.20 Multi-Agent Beta Reasoning from xAI has officially appeared on the Arena leaderboard, marking a notable step in competitive AI benchmarking. As reported by Arena.ai, the model secured #7 in the Search Arena category, alongside placements of #11 in Text Arena and #22 in Vision Arena.
The Arena system evaluates models based on real-world usage patterns rather than controlled lab conditions, and its results can be filtered across more specialized domains. What stands out about Grok 4.20's performance is how the numbers improve as task complexity increases.
Grok 4.20 Performs Strongest in Expert-Level AI Domains
According to the published leaderboard data, Grok 4.20 Multi-Agent Beta ranks #3 in Medicine and Healthcare, and #6 across Expert Prompts, Mathematical, and Legal and Government categories.
That gap between general and domain-specific rankings tells a clear story: the model is built to handle harder problems, and the evaluations reflect that.
The model shows stronger performance in higher-skill tasks, where domain-specific reasoning matters most.
These rankings are driven by user evaluations across practical use cases, which makes them a more reliable indicator of real-world utility than isolated benchmarks. The Search Arena placement in particular puts Grok 4.20 in direct competition with some of the most capable models currently available.
Grok 4.20 Enters a Competitive AI Leaderboard Field
The leaderboard confirms Grok 4.20's position among leading AI systems in a field where rankings shift quickly and margins are narrow. Performance here reflects how the model handles search and reasoning tasks under actual usage conditions - not synthetic test environments.
This milestone fits into a broader wave of development across the xAI Grok 4.20 API, which launched with a 2M token context window and 3 model variants, signaling that xAI is expanding the ecosystem aggressively.
Rankings based on user-driven evaluations reflect performance across practical search and reasoning tasks, not isolated benchmarks.
The Search Arena category is particularly significant because it tests how models handle queries that blend retrieval, reasoning, and response quality together - a combination that reflects how most people actually use AI tools today.
Grok 4.20 Search Arena Results in Context
Earlier coverage noted that Grok 4.20 Beta topped the Search Arena and edged out larger AI models - a result that now sits alongside the broader leaderboard picture showing consistent strength across expert categories.
The competitive pressure isn't limited to search and reasoning. Adjacent trends in the AI space point to accelerating momentum across development tooling as well, with Claude Code NPM downloads surging 70x and Codex installs reaching 5 million - underscoring just how fast real-world adoption is moving across the entire AI model landscape.
The #7 Search Arena ranking places Grok 4.20 inside a competitive field where the difference between positions often comes down to how well a model performs under complex, multi-step conditions.
The Grok 4.20 Multi-Agent Beta rankings reflect where xAI currently stands in the broader competitive picture - inside the top 10 for search, and notably higher when the prompts get harder.
 Eseandre Mordi
Eseandre Mordi


