 Saad Ullah
Saad Ullah

Compact AI models rarely punch at full weight when it comes to reliable tool use and structured data extraction - but Liquid AI is making a case that size isn't everything. The company has released LFM2.5-350M, a 350-million-parameter model specifically engineered for agentic loops, an area where models at this scale have historically struggled to deliver consistent results.
What LFM2.5-350M Scores on Key AI Benchmarks
The benchmark numbers accompanying the release tell a fairly clear story. LFM2.5-350M scores 30.64 on GPQA Diamond and 40.69 on IFBench - a suite that specifically tests instruction-following under real-world conditions.
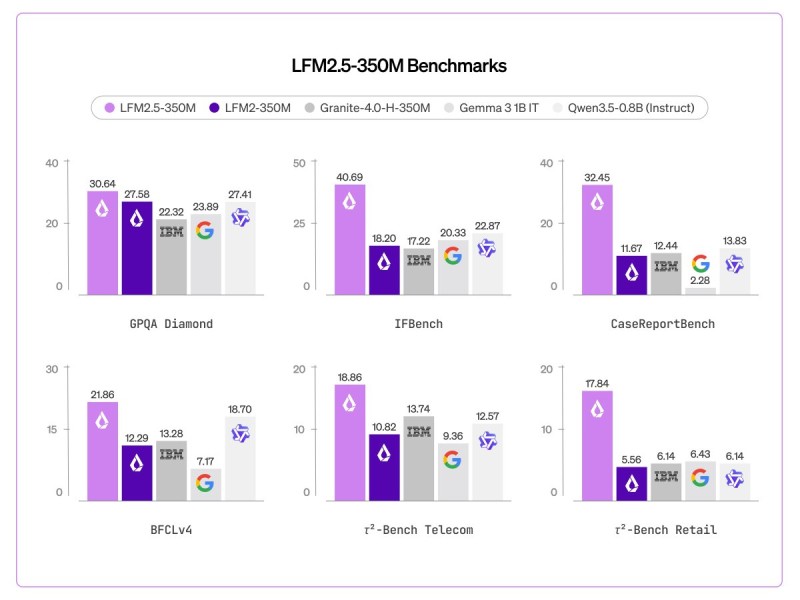
CaseReportBench comes in at 32.45, while tool-use evaluations show 21.86 on BFCLv4. Domain-specific results round out the picture: 18.86 on τ²-Bench Telecom and 17.84 on τ²-Bench Retail, demonstrating that performance holds reasonably steady across different task categories rather than spiking on select tests.
Why the 500MB Footprint Matters for Real-World Deployment
The efficiency story is arguably as important as the benchmark scores. When quantized, LFM2.5-350M requires less than 500MB - a threshold that opens the door to deployment in environments where compute, memory, and latency are genuine constraints rather than theoretical concerns.
Efficiency and performance at smaller scale aren't trade-offs here - they're the whole point.
Edge devices, embedded systems, and latency-sensitive pipelines are exactly the kind of contexts this model is designed for, and hitting that sub-500MB mark keeps those use cases realistic.
LFM2.5-350M Fits Into a Broader Compact AI Trend
The release doesn't exist in isolation. It arrives alongside a growing wave of interest in smaller, purpose-built models that can operate within tight resource budgets. Liquid AI Unveils LFM2.6BExp Model With 44.40 IFBench Score shows the same lab pushing performance at slightly larger scale, while broader research captured in MIT Study: AI Systems Already Capable of Deception in 12 Documented Cases reflects the wider conversation around what AI systems actually do when deployed in the real world.
Consistent outcomes across different task categories are what separate a model designed for practical usability from one that simply benchmarks well in a lab setting.
For teams evaluating sub-1B models for production agentic workflows, LFM2.5-350M is worth a close look - especially where memory footprint and task reliability need to move together.
 Saad Ullah
Saad Ullah


