 Peter Smith
Peter Smith

⬤ Liquid AI released LFM2-2.6B-Exp, an experimental checkpoint built from its LFM2-2.6B model using pure reinforcement learning. The company said this new version delivers solid gains in instruction following, knowledge tasks, and math benchmarks, competing at the top of the 3-billion-parameter model class. The release shows ongoing progress in getting more capability out of smaller models.
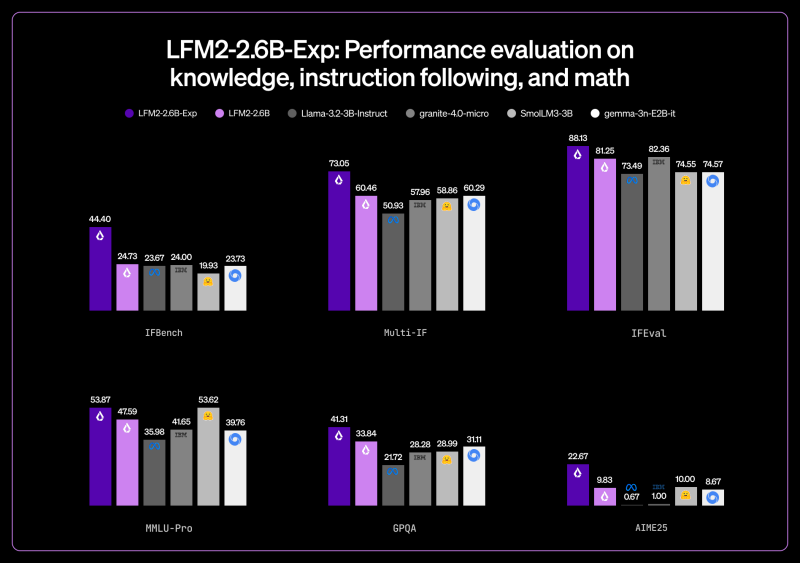
⬤ Published benchmarks show LFM2-2.6B-Exp hitting 44.40 on IFBench, jumping from 24.73 in the base model. Multi-IF climbed to 73.05 from 60.46, while IFEval improved to 88.13 from 81.25. MMLU-Pro results moved up to 53.87 from 47.59, and GPQA reached 41.31 versus 33.84. On AIME25 math tests, the model scored 22.67, outpacing several competing 3B systems including Llama-3-2-3B-Instruct, granite-4.0-micro, SmolLM3-3B, and gemma-3n-E2B-it. Liquid AI pointed out that the IFBench score beats DeepSeek R1-0528, a model 263 times larger.
⬤ Liquid AI credited these improvements to reinforcement-learning training applied to the original LFM2-2.6B architecture. The performance data shows consistent gains across knowledge, math, and instruction evaluations rather than strength in just one area. The company called LFM2-2.6B-Exp the strongest 3B-parameter model available in these tested categories.

⬤ The launch of LFM2-2.6B-Exp reflects continued advances in compact AI systems that deliver stronger performance at lower computational costs. As smaller models grow more capable, this development could reshape how organizations approach AI deployment, weighing capability requirements against cost and efficiency.
 Peter Smith
Peter Smith


