 Saad Ullah
Saad Ullah

⬤ Liquid AI just dropped a new lineup of on-device language models called LFM2, built specifically to crush it on edge deployments. These models range from 350 million all the way up to 8.3 billion parameters and pack up to 2× higher CPU throughput for both prefill and decode operations. The benchmark data shows these models forming a clean Pareto frontier—basically meaning they're hitting the sweet spot between speed and accuracy.
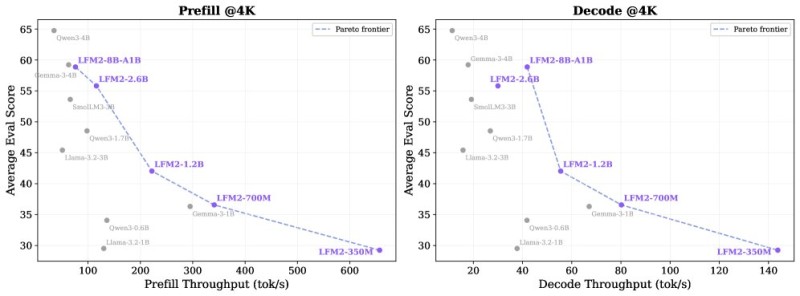
⬤ Looking at the "Prefill @4K" numbers, LFM2 models show a smooth climb between performance and quality. The lightweight LFM2-350M hits over 600 tokens per second in prefill throughput, while beefier versions like LFM2-1.2B, LFM2-2.6B and LFM2-8B-A1B deliver stronger evaluation scores at slightly lower speeds. Competing options from Qwen, Gemma and Llama are shown in gray, but LFM2 maintains a clear edge in CPU-constrained environments where memory limits are real constraints.
⬤ The "Decode @4K" results tell the same story. LFM2-350M pushes over 140 tokens per second in decode throughput, and mid-range models like LFM2-700M and LFM2-1.2B strike a solid balance between speed and accuracy. The larger LFM2 variants keep climbing in evaluation scores while staying competitive on decoding efficiency. These benchmarks signal growing traction for on-device AI, which wins big from higher throughput and less dependency on cloud inference.

⬤ This matters because better model efficiency is driving a major shift toward on-device AI. Gains in CPU throughput mean snappier responses, lower operational costs and wider adoption of edge applications—all factors reshaping market dynamics across the AI and semiconductor space.
 Saad Ullah
Saad Ullah


