 Usman Salis
Usman Salis

⬤A team from NVIDIA, MIT, UC Berkeley, and Clarifai has introduced AutoGaze, a preprocessing method that sits in front of existing AI video models and filters out redundant visual data before it ever reaches the main network. The system targets only frames where meaningful changes occur - ignoring static regions like walls or empty backgrounds entirely.
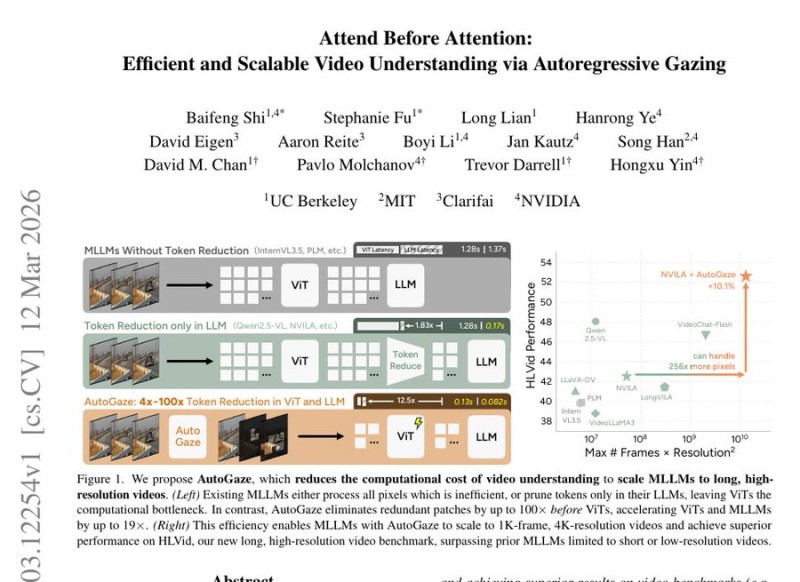
⬤The core problem it solves is real: today's multimodal models try to analyze every pixel in every frame, which gets brutal fast on long or high-resolution clips. A five-minute 4K video with roughly 1,000 frames used to demand massive compute. AutoGaze attacks this by stripping visual tokens before they hit the vision transformer, reducing token count by 4x to 100x depending on how much motion a video actually contains.
⬤The mechanism uses an autoregressive "gazing" process that evaluates frames at multiple zoom levels. Sections that lack motion or detail get skipped; the model only focuses tightly when something important is actually happening. The result: up to 19x faster processing with no meaningful drop in benchmark scores.
⬤AutoGaze fits into a broader trend in AI research - working smarter on data selection rather than just throwing more GPUs at the problem. Similar efficiency-focused work is appearing across the industry, including NVIDIA-backed projects in human motion generation and the company's open-source NemoClaw agent platform targeting enterprise AI deployments. The common thread: as models scale to handle richer multimodal inputs, preprocessing pipelines are becoming just as important as the models themselves.
 Usman Salis
Usman Salis


