 Peter Smith
Peter Smith

Nvidia has introduced Nemotron Super 120B-A12B, an open-weight large language model built to accelerate enterprise AI inference at scale. The launch was spotlighted by AI researcher Sebastian Raschka, who noted the model's strong benchmark results alongside its standout generation speed compared to competing open models.
Hybrid Architecture Powers Faster Inference
Nemotron Super runs on a 120-billion parameter framework with roughly 12 billion active parameters per token, built on a hybrid Mamba-Transformer Latent Mixture-of-Experts design. The architecture weaves together Mamba-2 layers, grouped-query attention modules, and Latent MoE expert routing -- activating only a subset of experts per inference pass. This keeps computational costs lean without sacrificing model capacity. Multi-token prediction baked into the design further cuts latency when processing long prompts.
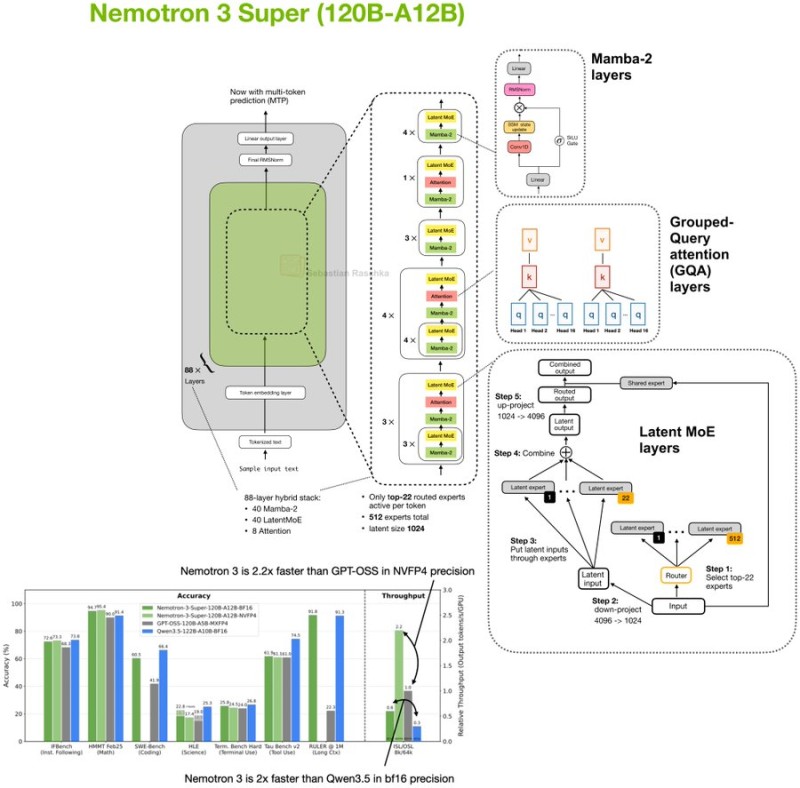
2.2x Throughput vs. GPT-OSS-120B, 1M-Token Context Window
Benchmark results place Nemotron Super on par with Qwen3.5-122B and GPT-OSS-120B across standard evaluation tasks -- but the real edge is throughput. Nvidia's documentation puts the model at up to 2.2x higher throughput than GPT-OSS-120B, with similarly strong gains over Qwen3.5 configs. The model also supports context windows of up to 1 million tokens, making it viable for long-document processing and multi-step reasoning pipelines. Full details on long-context capability and open-weight availability are covered in Nvidia launches Nemotron Super 120B open AI model with 1M-token context.
The release fits Nvidia's broader push to dominate the AI infrastructure stack. As generative AI spreads across industries, models pairing strong benchmarks with high throughput are moving from nice-to-have to essential. That hardware pressure is real -- Nvidia's next-gen Rubin chip already demands close to 300GB of RAM, a topic examined in depth in Nvidia's Rubin AI chip needs nearly 300GB of RAM -- up 800% vs desktop PCs. Nemotron Super signals where the company is heading: faster, leaner open models designed to make the most of its expanding hardware ecosystem.
 Peter Smith
Peter Smith


