 Eseandre Mordi
Eseandre Mordi

NVIDIA has unveiled Nemotron 3 Super, the flagship release in its newly announced Nemotron 3 family of open AI models. Built around 120 billion parameters, the system targets compute-efficient, high-accuracy multi-agent applications. Developers get full access to model weights, datasets, and training recipes, giving organizations real flexibility to customize and deploy within their own AI infrastructure.
Hybrid Mamba-Transformer Architecture Cuts Compute Without Sacrificing Accuracy
At the heart of Nemotron 3 Super is a hybrid architecture that pairs Mamba sequence modeling with Transformer layers and a Mixture-of-Experts (MoE) framework.
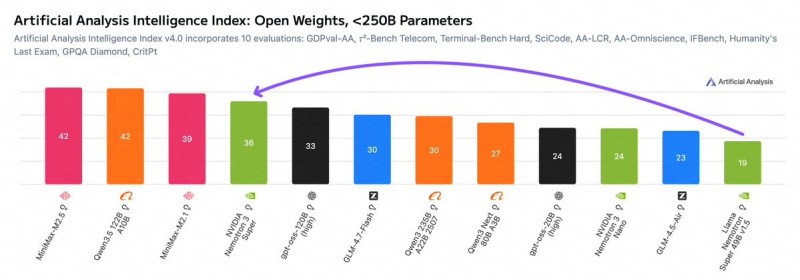
The model holds 120B total parameters but activates only a fraction during inference, keeping memory usage and compute costs in check.
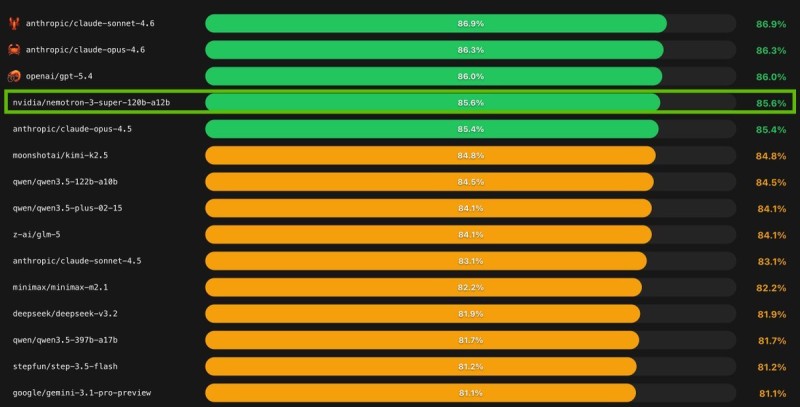
This combination of long-context sequence modeling and precise reasoning makes it well-suited for agent-based workloads where both speed and accuracy matter.
1 Million Token Context Window Powers Complex Agentic Workflows
Nemotron 3 Super ships with a native 1-million-token context window, letting it process massive document collections or multi-step workflows in a single pass. NVIDIA designed the entire Nemotron 3 family for "agentic" AI pipelines, where multiple models collaborate on planning, tool use, and extended reasoning. That focus on scalable multi-agent infrastructure is becoming a defining theme across the industry.
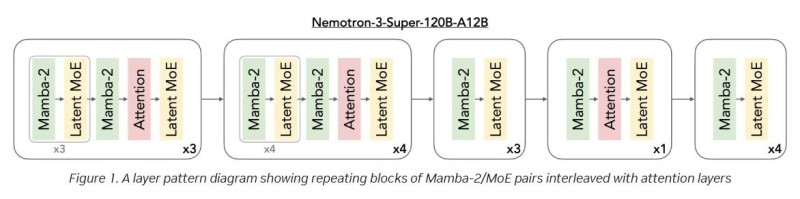
The launch extends NVIDIA's push beyond GPU hardware into the software layer of AI. By pairing open models with its dominant compute ecosystem, the company is building what it positions as a full-stack platform for enterprise and developer adoption. The pace of innovation in open model architectures is accelerating fast, as also seen in 0G Labs' verifiable on-chain AI infrastructure, signaling how rapidly the broader AI model ecosystem is shifting toward efficiency and scalability.
 Eseandre Mordi
Eseandre Mordi


