 Peter Smith
Peter Smith

⬤NVIDIA's latest language model, Nemotron 3 Nano, strikes an interesting balance between raw power and practical efficiency. The model scored 52 on the Artificial Analysis Intelligence Index while cleverly using a mixture-of-experts setup that only fires up about 3.6 billion parameters during actual use. Performance charts place it right alongside top models in its weight class, showing it can hang with both open-source and closed alternatives without breaking a sweat.
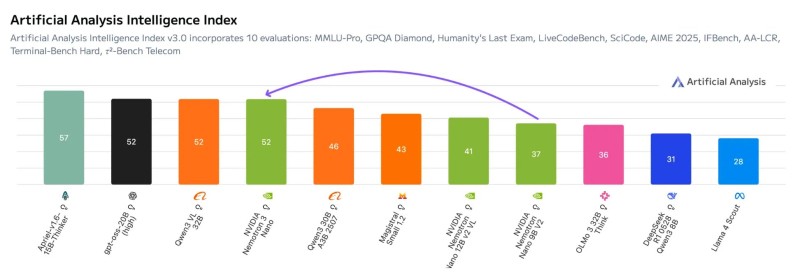
⬤Built on a hybrid Mamba-Transformer architecture with moderate-sparsity MoE routing, the model packs 31.6 billion total parameters but keeps things efficient by activating just 3.6 billion at runtime—especially helpful when dealing with longer context windows. Benchmark-wise, it matches OpenAI's gpt-oss-20b high configuration, beats Qwen3 30B A3B 2507 by six points, and crushes NVIDIA's earlier Nemotron Nano 9B V2 by fifteen points.
⬤NVIDIA isn't keeping this one locked down. Nemotron 3 Nano handles a massive one million token context window and offers both reasoning and non-reasoning modes. Released under the NVIDIA Open Model License for commercial use and derivatives, it scored 67 on the Openness Index thanks to published training methodology. You can grab it through serverless inference providers or download it from Hugging Face for local deployment.

⬤For anyone tracking NVDA, this release signals NVIDIA's push to bundle cutting-edge hardware with smart, efficient AI models. Getting solid benchmark numbers from models with relatively few active parameters shows they're serious about inference efficiency. As businesses hunt for cost-effective deployment options with long-context capabilities, models like Nemotron 3 Nano could reshape how developers think about scaling NVIDIA's AI ecosystem.
 Peter Smith
Peter Smith


