 Alex Dudov
Alex Dudov

● IBM researcher merve recently shared news that the Granite research team has dropped their Granite 4 Nano models — compact AI systems built for efficiency without sacrificing performance. The standout? Granite-4.0-1B crushes Qwen3-1.7B on reasoning, math, and code generation benchmarks, despite being significantly smaller.
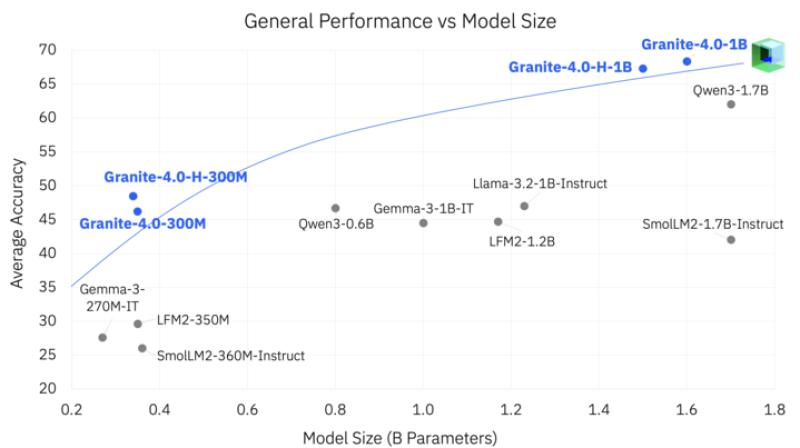
● IBM's approach flips the conventional wisdom on its head. Instead of just making models bigger, they've focused on smarter architecture and training techniques. It's proof that you don't always need massive models to get great results. That said, some experts wonder if these ultra-compact models might struggle with longer contexts or highly specialized tasks that enterprise customers need.
● The business case is compelling. As AI training costs spiral out of control, IBM's Granite 4 Nano offers a cheaper alternative to power-hungry giants. Better performance per parameter means lower energy bills and less demanding hardware — making these models practical for on-device applications, enterprise deployments, and research projects.
● Granite-4.0-H-300M, Granite-4.0-300M, Granite-4.0-H-1B, and Granite-4.0-1B (marked in blue on IBM's charts) all punch above their weight class. They consistently beat larger competitors like Gemma-3, Llama-3.2-1B-Instruct, SmolLM2-1.7B-Instruct, and Qwen3-1.7B. IBM's showing the industry how to squeeze more capability out of fewer parameters.
● According to the announcement: "the 1B variant outperforms Qwen3-1.7B with fewer parameters on a mix of tasks from math to coding." It's a significant moment for IBM's open-model strategy — demonstrating that lean, efficient architectures can compete with (or even beat) much larger systems.
 Alex Dudov
Alex Dudov


