 Usman Salis
Usman Salis

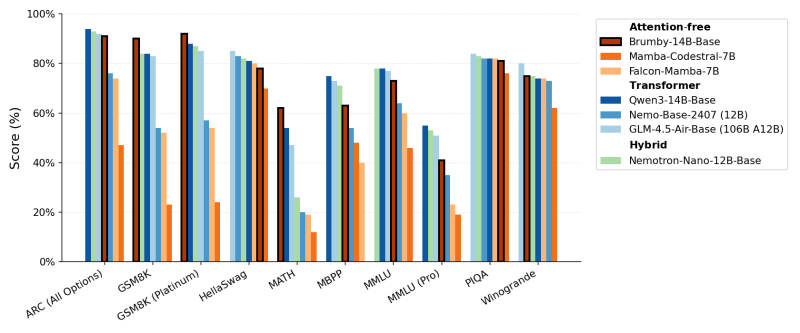
● Researcher Jacob Buckman recently shared results that could reshape how we think about training large language models. His Brumby-14B Base — a 14-billion-parameter model built without traditional attention mechanisms — was trained for only $4,000, yet performs comparably to leading transformer and hybrid architectures. This challenges the assumption that transformers are the only path forward for high-performing AI.
● Brumby-14B ditches the attention mechanism — the core technology behind GPT-style transformers — and uses a state-space approach instead. This makes training faster and cheaper, but rapid adoption could disrupt existing tools, optimization workflows, and developer expertise — creating short-term friction across the AI ecosystem.
● The cost implications are massive. Training a typical 14B transformer runs into hundreds of thousands of dollars. Brumby-14B delivers comparable performance for just $4,000 — roughly 1% of traditional costs. This shifts AI development priorities from massive compute budgets toward smarter algorithms and better data efficiency — a "cost-optimization revolution" rather than a scaling arms race.
● Benchmark results show Brumby-14B scoring 80-90% across key reasoning and language tasks (ARC, GSM8K, MMLU, PIQA) — matching established models like Qwen3-14B, GLM-4.5-Air-Base, and Nemotron-Nano-12B. This proves attention-free architectures can now compete with top transformers without massive compute budgets, marking a significant turning point toward efficiency-first AI development.
● As the researcher put it, "the end of the transformer era marches slowly closer." This statement captures both the technological progress and the paradigm shift underway — as the AI community increasingly explores attention-free models that promise comparable intelligence at a fraction of the cost.
● AI model, Transformer alternatives, Brumby-14B, Attention-free models, AI efficiency, State-space models, Foundation models, AI benchmarks, Cost-effective AI
 Usman Salis
Usman Salis


