 Saad Ullah
Saad Ullah

OpenAI's GPT-5.3 Codex benchmark performance has claimed the top position on PinchBench, a new open-source evaluation framework developed by Kilo Code. The benchmark tests large language models across 23 OpenClaw automation tasks including scheduling meetings, writing code, and triaging emails — measuring how well AI systems handle practical workflows rather than purely academic datasets.
97.8% Success Rate Puts GPT-5.3 Ahead of Gemini and Claude
GPT-5.3 Codex achieved a 97.8% success rate. Google's Gemini-3 Flash came in second at 95.1%, followed by MiniMax M2.1 at 93.6% and Moonshot AI's Kimi-K2.5 at 93.4%. Several Anthropic models, including Claude Sonnet and Claude Opus variants, also scored above 90%, reflecting an increasingly competitive field among frontier AI systems.
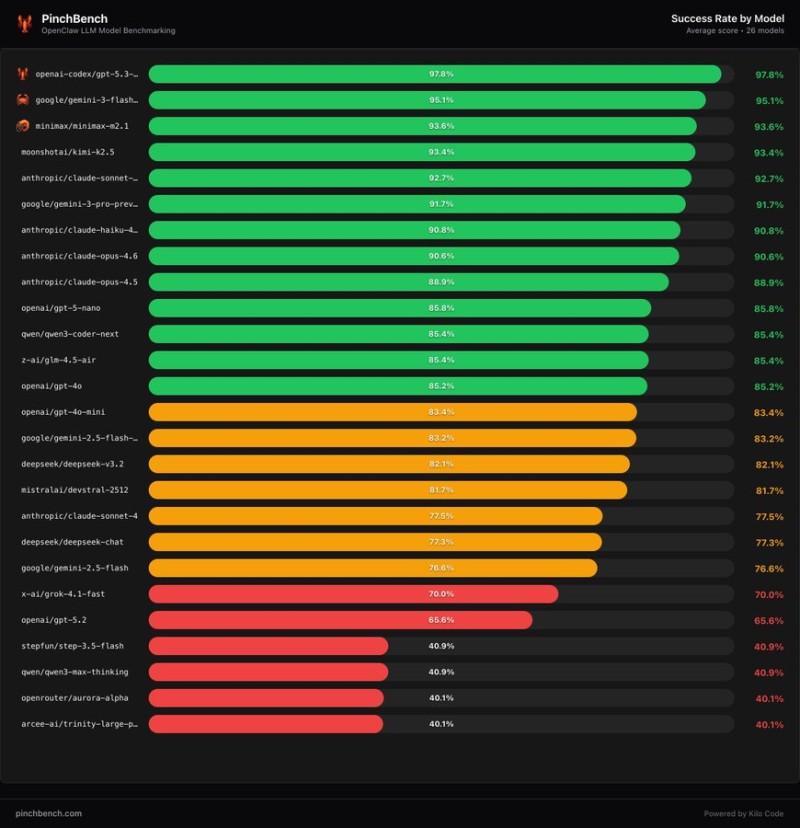
Why Practical Benchmarks Are Replacing Academic Tests
PinchBench focuses on agent-style workflows that simulate everyday productivity scenarios. Models are evaluated on multi-step actions: coordinating calendars, managing inbox messages, and generating working code solutions. This mirrors a broader industry shift away from purely theoretical evaluations toward assessments that reflect enterprise automation environments.
With GPT-5.3 Codex leading the new ranking, competition in the AI infrastructure market shows no signs of slowing. Developers are now focused on real-world agent capabilities, and major upcoming AI model launches including GPT-5.3 are expected to push performance benchmarks even higher across the industry in the months ahead.
 Saad Ullah
Saad Ullah


