 Peter Smith
Peter Smith

⬤ OpenAI's GPT-5.3 Codex just grabbed the crown on the WeirdML benchmark, pulling off a 79.3 percent score across 17 different tasks. That puts it slightly ahead of Anthropic's Claude Opus 4.6 (adaptive), which landed at 77.9 percent. The interactive WeirdML comparison shows GPT-5.3 Codex sitting at the top of the pack, beating out heavyweights like GPT-5.2, Gemini 3.1 Pro, and other cutting-edge models.
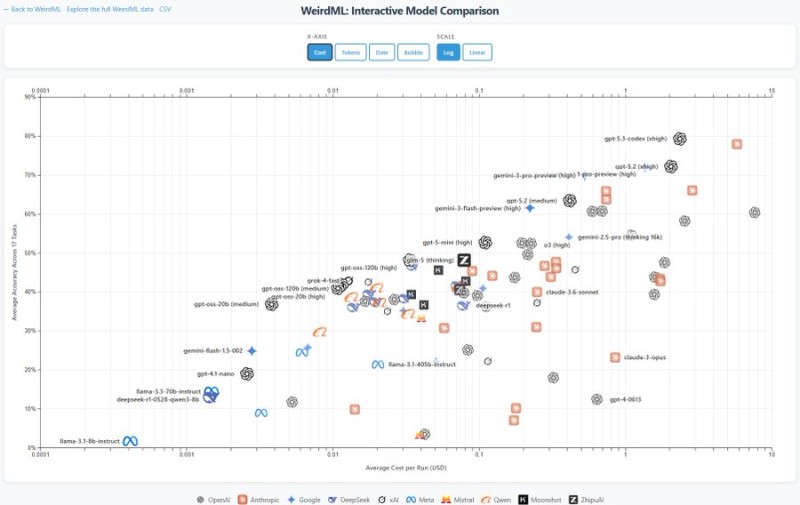
⬤ What's really interesting here is the cost side of things. GPT-5.3 Codex isn't just winning on accuracy - it's doing it for about $2.35 per run. Compare that to Claude Opus 4.6, which costs nearly $5.78 per run, and you start to see why this matters. When you plot average accuracy against cost, GPT-5.3 Codex sits right at that sweet spot where elite performance meets reasonable pricing.
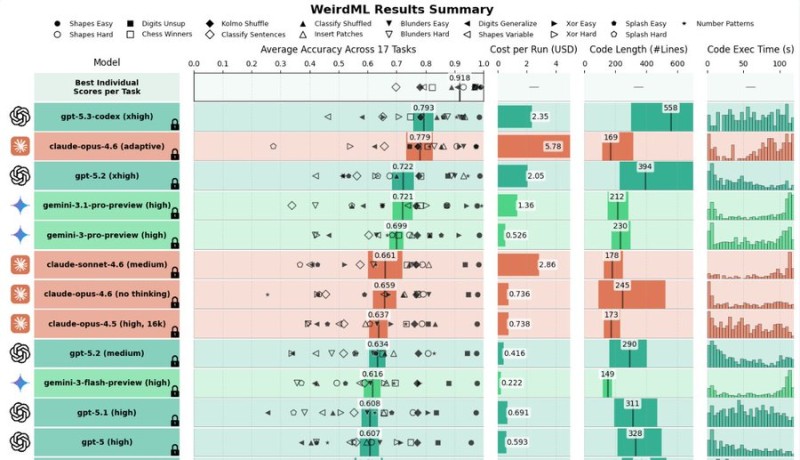
⬤ That said, the benchmark data shows some nuance worth mentioning. While GPT-5.3 Codex takes the overall win, models like Gemini 3.1 Pro might actually outperform it on specific individual tasks - they just don't maintain that level across the board. This creates a pretty fierce competitive landscape among OpenAI, Anthropic, Google, and other major players. Independent testing also backs up GPT-5.3 Codex's strength on longer reasoning tasks, which adds another layer to its performance story.
⬤ Why does this benchmark matter so much? Because WeirdML gives us a transparent look at how these models actually perform across diverse, real-world tasks. When a model leads on this kind of multi-dimensional testing, it influences everything from which AI tools enterprises choose to adopt, to how cloud providers structure their services, to where research labs focus their next development efforts. As AI companies keep pushing boundaries on both capability and cost, results like these help everyone understand where the field actually stands right now.
 Peter Smith
Peter Smith


