 Eseandre Mordi
Eseandre Mordi

⬤ OpenAI's GPT-5.3-Codex just posted some impressive numbers on extended software tasks. According to a new evaluation by METR, the model hits a 50-percent time horizon of roughly 6.5 hours, meaning it can complete half of tested programming and reasoning assignments within that window. The research used API access provided by OpenAI, and the results point to a clear step forward in long-duration task execution compared to earlier model generations.
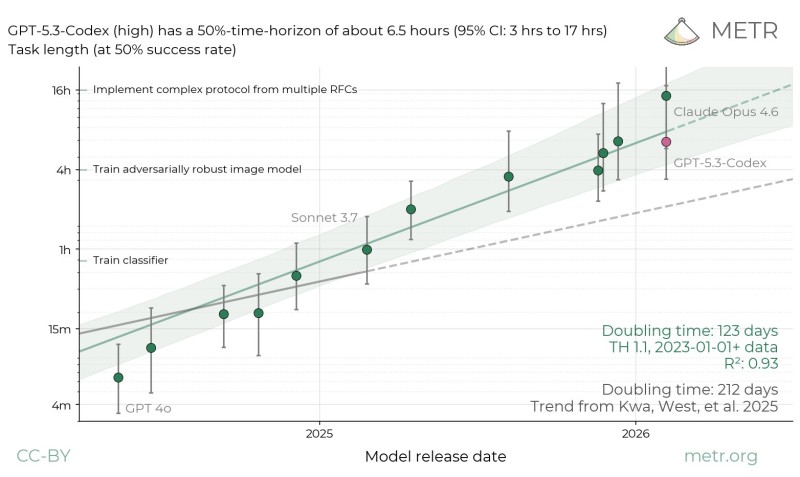
⬤ The METR evaluation chart tracks task length at the 50% success rate across model release dates, and GPT-5.3-Codex sits toward the high end of that curve. The data suggests a doubling time of around 123 days in task horizon capability, which is a striking pace of improvement. This fits a broader trend: models like Claude Opus 4.6 are also extending their operational reach on demanding benchmarks. OpenClaw has already added support for both Opus 4.6 and GPT-5.3-Codex, reflecting how quickly the ecosystem is moving to integrate these advanced reasoning models.
⬤ The competitive picture is shifting fast. Claude Opus 4.6 currently leads SWE-Bench with a strong 51.7 score, while GPT-5.3-Codex ranks among the top performers on extended task suites. These rankings highlight how both reasoning effort and raw endurance are becoming the key differentiators at the frontier.
⬤ The story isn't just about large models, either. Compact architectures like NanBeige-4.1-3B are hitting 87.4% scores and outperforming 32B systems, showing that efficiency gains are happening across the board. Together, these developments paint a picture of an AI landscape where multi-hour autonomous task completion is quickly becoming the norm rather than the exception, with real consequences for how teams think about coding assistants, automated reasoning pipelines, and long-horizon AI workflows.
 Eseandre Mordi
Eseandre Mordi


