 Peter Smith
Peter Smith

⬤ Claude Opus 4.6 is turning heads in the AI world after fresh benchmarking data revealed something interesting - while it doesn't win on pure horsepower, it holds up way better when tasks drag on. 0xMarioNawfal pointed out that Opus 4.6 "isn't the highest on raw alpha," but "degrades slower than almost every other model." That means when you're running marathon-length tasks, this model keeps delivering while others start falling apart. The new success probability curves compare how different AI models perform as task duration stretches out, and Claude Opus 4.6 leads Swerebench with 517 score fits right into this pattern of excelling at sustained work.
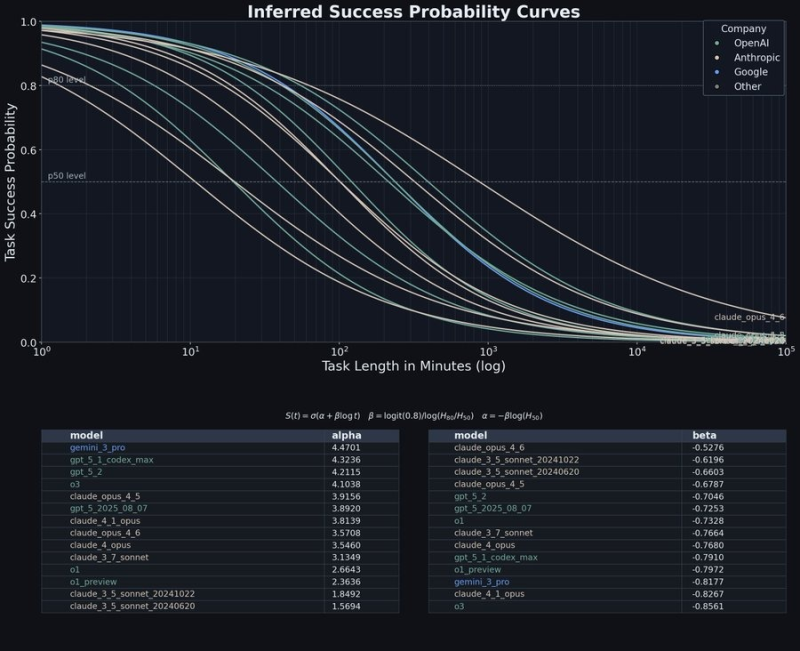
⬤ The visualization tracks success rates against task length on a log scale, showing most models nosedive as time requirements grow. Alpha values show each model's starting strength, while beta coefficients reveal how fast they decay. Claude Opus 4.6 doesn't top the alpha charts, but its beta values tell a different story - it bleeds performance much slower than the competition. At extended time horizons, where other models' curves crash toward zero, Opus 4.6 keeps chugging along with noticeably higher success probabilities. The gap becomes really obvious once you hit tens of thousands of minutes of task length.
The long-horizon advantage becomes more evident at extended time horizons, where sustained reasoning separates leaders from the pack.
⬤ This shift matters because it shows the industry moving beyond quick-hit metrics toward valuing reliability over the long haul. Sure, some models crush short tasks, but Claude Opus 4.6's sweet spot is multi-stage reasoning and workflows that don't quit. We're seeing similar innovation waves across AI - MOVA AI Model introduces multimodal video/audio generation and Google's 100-megawatt space AI data center plan both point to infrastructure built for complexity, not just speed. As applications get more demanding, lasting power starts mattering more than flash.
⬤ The focus on long-duration performance reflects how AI evaluation is evolving. When developers push models into enterprise workflows requiring extended reasoning and workflow continuity, metrics capturing longevity complement traditional benchmarks. It's a rebalancing of what success means in AI - not just how fast you sprint, but whether you can finish the marathon without collapsing halfway through.
 Peter Smith
Peter Smith


