 Eseandre Mordi
Eseandre Mordi

Real-World Coding Performance Takes Center Stage
The latest SWE-ReBench evaluation has shaken up how we measure AI coding capabilities, moving beyond traditional verified benchmarks to test real-world software engineering skills. The results paint an interesting picture of where today's leading models actually stand when faced with practical coding challenges.
Claude Opus 4.6 Claims Top Spot with 51.7% Performance
Fresh SWE-ReBench testing put several major coding AI models through their paces, including Claude Opus 4.6, MiniMax M2.5, and Qwen3-Coder-Next. Unlike standard benchmark scores, this evaluation focuses squarely on actual software engineering performance in realistic scenarios.
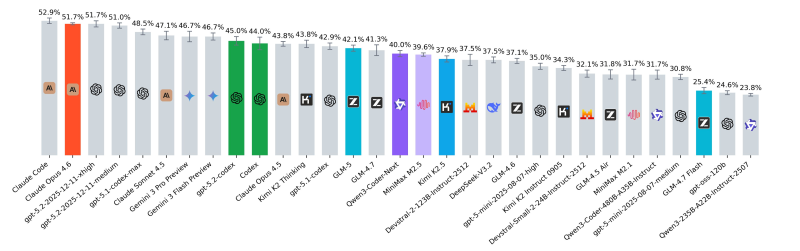
Claude Opus 4.6 emerged as the clear leader, posting approximately 51.7% on the benchmark. This performance gap becomes even more notable when you look at how other models fared in comparison.
MiniMax M2.5 Shows Gap Between Verified Benchmarks and Real Performance
MiniMax M2.5 demonstrated why benchmark scores don't always translate to real-world performance. Despite previously claiming 80.2% on SWE-bench verified—just slightly behind Opus 4.6's 80.8%—the model managed only around 39.6% on this more practical test.
This significant drop reveals an important truth: verified benchmark performance and actual software engineering capabilities can diverge substantially.
Qwen3-Coder-Next Punches Above Its Weight Class
Qwen3-Coder-Next delivered perhaps the most impressive results relative to its size. Running on an 80B A3B parameter configuration, the model hit approximately 40% on the benchmark—showing competitive performance despite having fewer parameters than many of the larger models in the evaluation.
This efficiency matters for developers choosing between model size, cost, and actual performance in production environments.
What These Results Mean for Software Development
The SWE-ReBench evaluation underscores a critical point: traditional benchmarks may not capture the full picture of coding AI performance. When models face real software engineering tasks, their capabilities can vary significantly from their paper scores.
For teams evaluating coding AI models for production use, these results suggest looking beyond verified benchmark numbers to consider practical performance metrics that better reflect actual development workflows.
 Eseandre Mordi
Eseandre Mordi


