 Peter Smith
Peter Smith

⬤ Independent SWE-rebench evaluations have dramatically reshaped how AI coding models stack up against each other. Several hyped Chinese releases performed far weaker than their initial SWE-bench verified scores suggested. The new benchmark shows leading frontier models hovering around the low-50% range, with Claude Opus 4.6 hitting approximately 51.7%.
⬤ The gap between marketing and reality is stark. M2.5 previously claimed about 80.2% on SWE-bench verified—nearly matching Opus 4.6's 80.8%—but scores significantly lower under stricter real-world evaluation. Meanwhile, Qwen3-Coder-Next manages around 40%, showing solid performance for its parameter size but still trailing top-tier systems. Recent improvements in coding reliability tie back to upgrades detailed in Anthropic Opus 4.6 research upgrade.
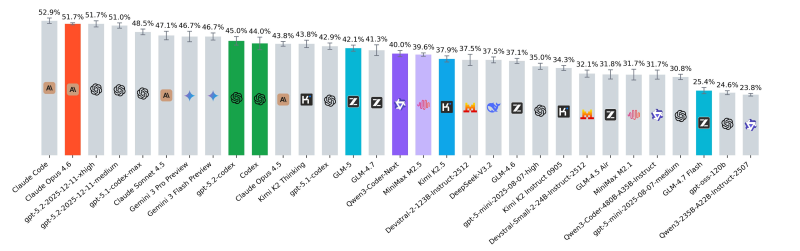
⬤ Current rankings reveal frontier models clustering between roughly 45% and 52%, while mid-tier options fall into the 25% to 40% band. This distribution matters because it represents actual coding task completion, not just pattern matching on test sets. Multi-agent approaches described in Claude Code multi-agent development workflow show how tooling evolution could shift future benchmark dynamics.
⬤ These results directly impact enterprise adoption decisions. Coding benchmarks influence which AI tools companies integrate into development pipelines and how much infrastructure they allocate. Performance shifts alter competitive positioning among model providers and reshape platform selection across software engineering environments. The tightening race suggests no single model dominates—instead, organizations must weigh trade-offs between raw performance, cost, and deployment complexity when choosing their AI coding stack.
 Peter Smith
Peter Smith


