 Peter Smith
Peter Smith

Nvidia's newest generation of graphics processing units is setting new standards for artificial intelligence performance. Recent benchmarks demonstrate that DeepSeek's advanced language models running on GB300 hardware achieve remarkable speed improvements that could reshape how companies deploy AI systems at scale.
DeepSeek R1 Hits 8x Prefill Speed on Nvidia's Latest Hardware
Nvidia's GB300 GPUs are delivering major performance gains for AI inference tasks as DeepSeek models reach unprecedented throughput levels. DeepSeek R1 processed approximately 22.5K prefill tokens per second and around 3K decode tokens per second per GPU using vLLM infrastructure, marking a substantial jump from Hopper-generation chips.
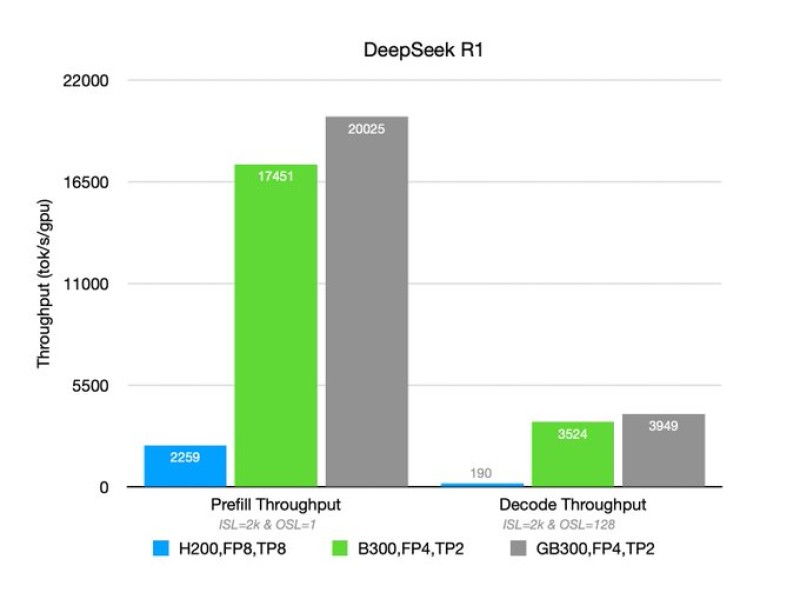
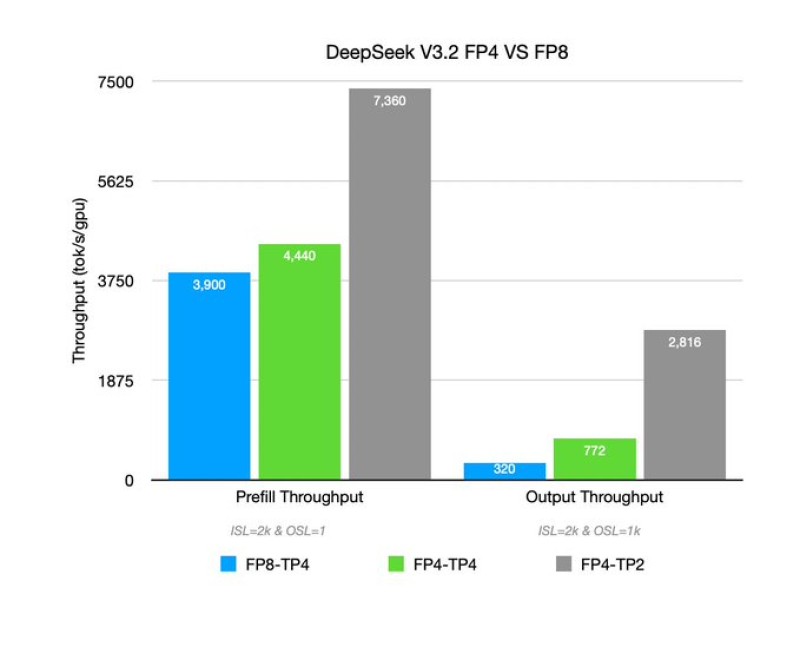
The benchmark results reveal roughly 8x improvement in prefill throughput and between 10x to 20x gains in mixed-context workloads compared to older architectures. Separate testing with DeepSeek V3.2 running on two GPUs generated about 7.4K prefill tokens per second and approximately 2.8K decode tokens per second. The configuration utilized NVFP4 weights from HuggingFace combined with FlashInfer FP4 MoE kernels and tensor parallelism, proving that software optimization working alongside hardware design drives performance scaling rather than raw chip power alone.
These developments extend beyond DeepSeek's core models. Recent launches like DeepSeekOCR 2 advanced reasoning model demonstrate expanding multimodal capabilities, while supporting infrastructure such as the Engram memory lookup system shows efforts to reduce computational waste and optimize long-running reasoning tasks.
Why Faster AI Inference Matters for Enterprise Deployment
Additional concurrency tests illustrate throughput scaling from roughly 3.5K tokens per second at low parallelism to nearly 12K tokens per second under higher concurrent loads. This efficiency matters because inference performance increasingly defines competitiveness in AI deployment.
Faster token generation directly lowers compute costs per query and enables real-time reasoning, automation workflows, and multi-agent orchestration systems. As AI models evolve beyond simple chat interfaces toward persistent reasoning platforms, hardware capable of high concurrency and long-context processing becomes foundational infrastructure. These results reinforce Nvidia's position in the expanding AI compute ecosystem, particularly as enterprises seek cost-effective ways to deploy sophisticated language models at scale.
 Peter Smith
Peter Smith


