 Marina Lyubimova
Marina Lyubimova

⬤ DeepSeek just dropped details on Engram, a fresh take on AI architecture that fundamentally changes how models access stored information. Here's the problem with current transformer models: they waste tons of compute re-deriving basic facts through multiple neural layers, essentially doing the same math over and over. Engram fixes this with conditional memory, letting models grab frequently used info directly rather than reconstructing it every single time.
⬤ The magic happens through N-gram embeddings stored in massive embedding tables. These enable O(1) deterministic lookup, meaning the model retrieves information in one step instead of grinding through multiple attention layers. This eliminates what DeepSeek calls "static reconstruction" - the endless regeneration of simple facts that burns compute without adding any actual reasoning power. The payoff? Early transformer layers stop wasting time on trivial tasks, freeing up deeper layers to handle genuinely complex reasoning.
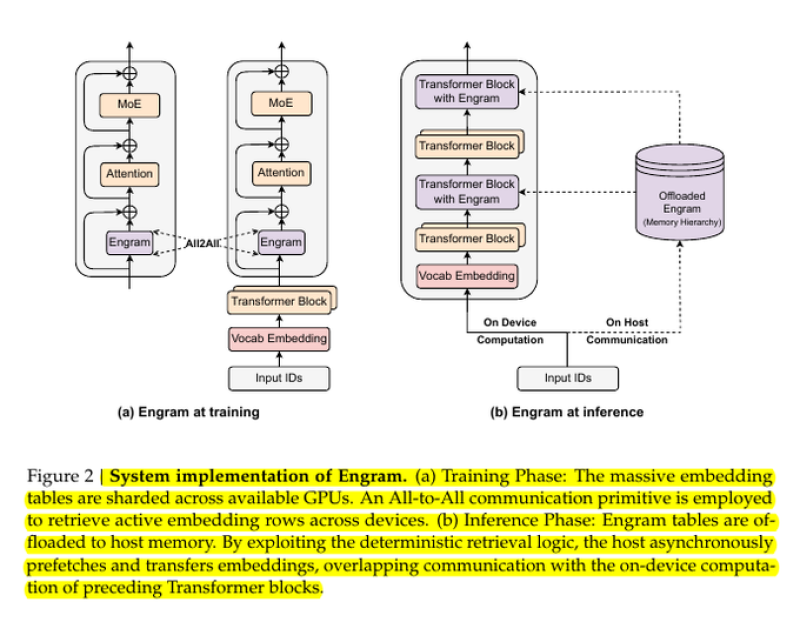
⬤ The system works differently during training versus inference. During training, huge embedding tables get sharded across available GPUs and accessed through all-to-all communication to pull active embedding rows. At inference time, these Engram tables move to host memory, where deterministic addressing lets the system asynchronously prefetch embeddings while on-device transformer blocks keep crunching numbers. This overlap between communication and computation means you can efficiently use CPU RAM as backup storage, taking pressure off limited GPU memory.

⬤ Engram represents a smarter approach to AI infrastructure. By splitting memory retrieval from reasoning and enabling predictable data access, it redirects compute power toward tasks that actually benefit from deep neural processing. The result is better performance in reasoning, coding, and math - not by throwing more compute at the problem, but by using what you've got more intelligently.
 Marina Lyubimova
Marina Lyubimova


