 Sergey Diakov
Sergey Diakov

⬤ DeepSeek just dropped its latest AI systems — V3.2 and V3.2-Speciale — and they're built specifically for complex reasoning tasks. The vLLM project rolled out full support for these models, including custom tokenizer modes, tool-call parsing, and native thinking-mode compatibility. The V3.2 replaces the earlier V3.2-Exp version, while Speciale takes structured reasoning capabilities to another level.
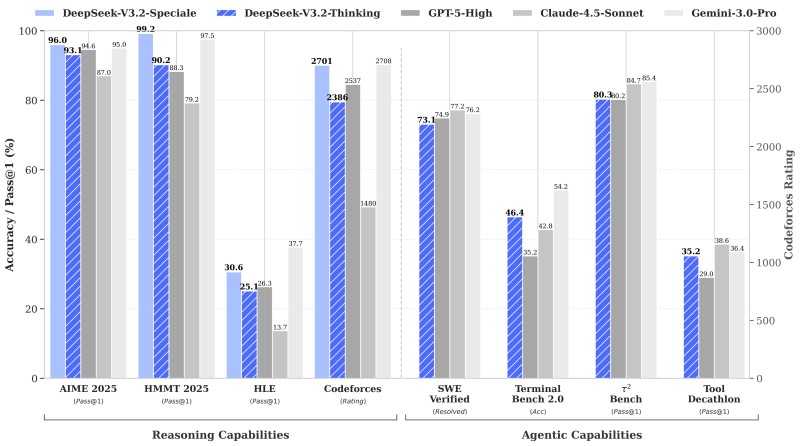
⬤ The numbers tell an impressive story. DeepSeek-V3.2-Speciale scored 96.0% on AIME 2025 and 99.2% on HMMT 2025, beating GPT-5-High, Claude-4.5-Sonnet, and Gemini-3.0-Pro across the board. On coding challenges, it reached a 2701 Codeforces rating — ahead of GPT-5-High's 2537, though slightly behind Claude-4.5-Sonnet's 2708. For agentic tasks, Speciale hit 46.4% on Terminal Bench 2.0 and 80.3% on τ² Bench, showing real gains in multi-step reasoning and tool usage.
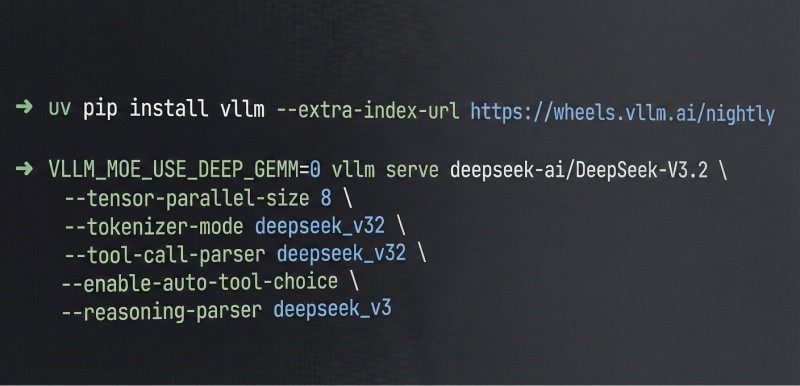
⬤ The new vLLM recipe makes it easier for developers to tap into DeepSeek's full reasoning capabilities with minimal setup. It includes DeepSeek-specific tokenizer and parser modules, optional reasoning-parser support, and automatic tool selection. Tencent Cloud provided compute resources to help optimize the deployment process.

⬤ These updates put DeepSeek-V3.2 in a stronger position for high-end reasoning and agentic workloads. The improvements in accuracy, coding ability, and structured problem-solving reflect the rapid pace of innovation happening right now in AI development, and they're already shifting how organizations think about deploying next-generation systems for complex operational tasks.
 Sergey Diakov
Sergey Diakov


