 Marina Lyubimova
Marina Lyubimova

⬤ DeepSeek v3.2 draws attention because it matches GPT-5 and Gemini 3 Pro while using about one thirtieth of the compute budget. The advance rests on a new sparse attention scheme that removes needless work yet keeps output quality. Diagrams released by researchers illustrate a lean pipeline that switches on only the data points required for the current step.
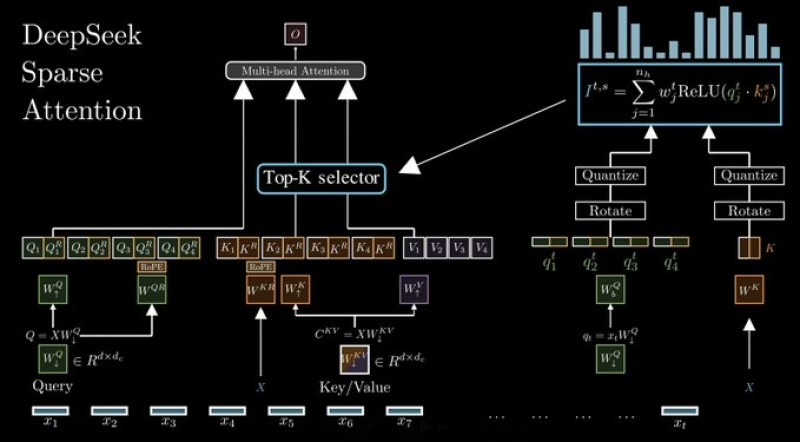
⬤ Classic attention schemes stall on long sequences - their Key-Value cache swells until memory runs out. DeepSeek counters this with three tools - multi query attention, grouped query attention plus an in house sparse pattern. Data first flows through a multi head module - a Top-K gate then retains only the vectors that matter. Those vectors are quantized and rotated - memory and compute shrink while scores stay the same.
⬤ The gain is clearest in long context jobs. By touching a tiny share of key value pairs at each step, the model keeps language, vision but also reasoning scores high without the heavy burn seen elsewhere. An internal scorer pinpoints and ranks the parts of the input that deserve focus.
⬤ This efficiency push mirrors the wider trend. Labs now trade brute scale for sparse tricks as well as smarter attention - victory goes to models that deliver power without waste. DeepSeek shows that deep cost cuts and top performance coexist, a point that matters as businesses race to deploy large language models in everyday products.
 Marina Lyubimova
Marina Lyubimova


