 Usman Salis
Usman Salis

Efficient fine-tuning of large language models has hit a persistent bottleneck: in Mixture-of-LoRAs architectures, most adapters end up ignored while just one or two dominate every decision. Researchers have now introduced ReMix, a reinforcement-based routing framework that addresses this collapse directly and restores the expressive potential of modular LLM training.
What Causes Routing Collapse in Mixture-of-LoRAs Systems
In Mixture-of-LoRAs setups, multiple low-rank adapters attach to transformer layers, letting a base model specialize across tasks without retraining billions of parameters. A router selects which adapters activate for each input.
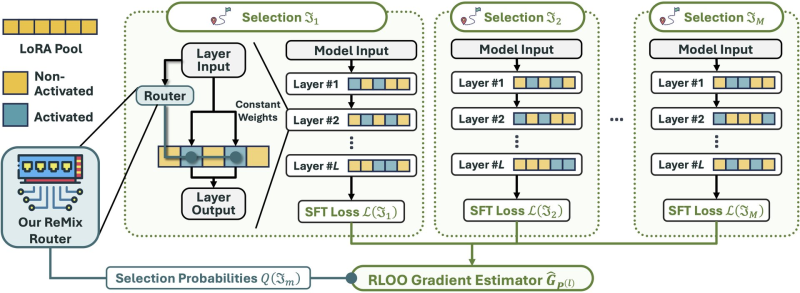
The problem: learnable routing weights become heavily imbalanced during training, effectively disabling most adapters and cutting model expressiveness. ReMix was built to fix exactly that. The broader push toward lightweight architectures is visible in projects like Nanbeige-4-13B, which hit an 87.4 benchmark score while outperforming 32B systems.
The ReMix team replaces learnable routing weights with fixed constant weights, so every active LoRA adapter contributes equally. Since constant routing cannot be optimized through gradient descent, they reframe router training as a reinforcement learning problem, applying an RLOO (Reinforce Leave-One-Out) gradient estimator. This approach estimates gradients from supervised fine-tuning loss signals, balancing adapter usage while preserving LoRA's efficiency advantages. Concerns about maintaining oversight over increasingly modular AI systems have been explored in research on AGI optimization risks and the limits of oversight.
Why ReMix Matters for Scalable LLM Fine-Tuning
By stabilizing routing across adapter pools, ReMix enables more balanced utilization of modular components without sacrificing computational efficiency. The framework signals a broader shift: rather than retraining entire models, AI systems increasingly rely on specialized adapter modules that can be composed and activated selectively. How that modularity reshapes AI-related labor is already playing out, with roles most exposed to language models growing 93% since the ChatGPT launch.
As research into parameter-efficient training matures, improved routing methods like ReMix could become central to how next-generation models are built. Keeping all adapters active and fairly weighted is a small architectural fix with potentially large downstream effects on model flexibility and task generalization.
 Usman Salis
Usman Salis


