 Marina Lyubimova
Marina Lyubimova

⬤ A new web agent benchmark has completely reshuffled the competitive landscape for AI systems built to navigate real online environments. The TinyFish web agent just claimed the top spot with results that left major lab systems trailing far behind on complex, multi-step web tasks.
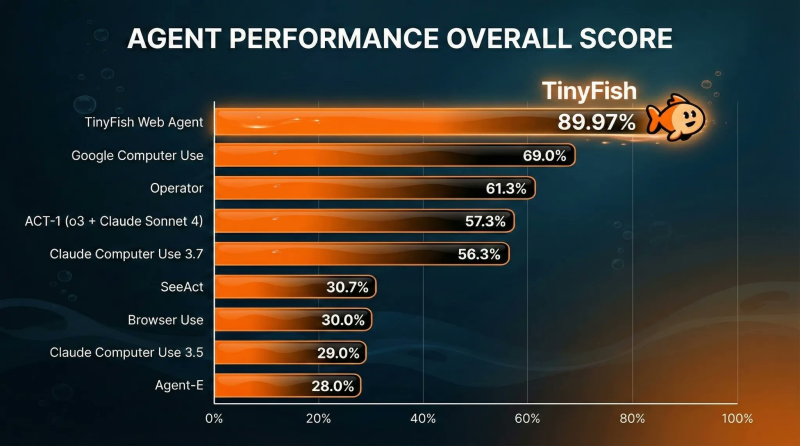
⬤ TinyFish posted an 89.97% score—a commanding lead over Google Computer Use at 69.0%, Operator at 61.3%, and ACT-1 running Claude Sonnet 4 at 57.3%. Claude Computer Use 3.7 came in at 56.3%, while a cluster of other agents hovered between 28% and 31%. That's a gap of more than 20 points separating TinyFish from the closest big-lab contender: +21 over Google, +29 over OpenAI-linked systems, and +34 over Anthropic-related agents. The performance gap signals broader shifts happening in autonomous agent design, explored further in agent world model architecture shift.
⬤ This benchmark doesn't test canned responses—it measures how reliably agents actually complete chains of actions across live web interfaces. Real-world deployment is already ramping up fast, as seen in AI agents expanding software development usage, where automated workflows are taking over more and more practical tasks.
⬤ Why this matters: performance differences this large in operational agents can flip platform adoption decisions and reshape where computing resources flow across AI ecosystems. As autonomous systems start handling genuine workflows, competitive standing among providers increasingly hinges on nailing reliable multi-step execution—not just conversational polish.
 Marina Lyubimova
Marina Lyubimova


