 Eseandre Mordi
Eseandre Mordi

⬤ Nanbeige LLM Lab just dropped their open-weight Nanbeige4.1-3B model under an Apache 2.0 license, and it's turning heads. According to Rohan Paul, this 3-billion-parameter system is outperforming comparable Qwen models across the board—from alignment and reasoning to coding and deep-search tasks. For context on how this fits into the broader landscape, check out Qwen launches 80B model with 1M-token context.
⬤ The numbers tell an impressive story. Nanbeige4.1-3B scored 73.2 on Arena-Hard-v2 and 52.2 on Multi-Challenge—benchmarks specifically designed to test how well smaller models handle chat preferences. When it comes to agent-style deep-search tasks, the model hit about 69.9 on GAIA and around 75 on xBench-DeepSearch-05. Those scores leave Qwen3-4B-2507 trailing significantly in the same evaluations. You can dive deeper into the performance metrics in tiny AI model Nanbeige4.1-3B achieves 87.4 score.
⬤ Where Nanbeige really shines is coding. The model achieved an 85% pass rate on LeetCode Weekly Contests 484–488. Compare that to Qwen3-4B-2507's roughly 55% and even Qwen3-32B's approximately 50% under identical testing conditions. The model handles context windows stretching up to 256k tokens, making it capable of managing deep search workflows packed with hundreds of tool calls and extended reasoning chains.
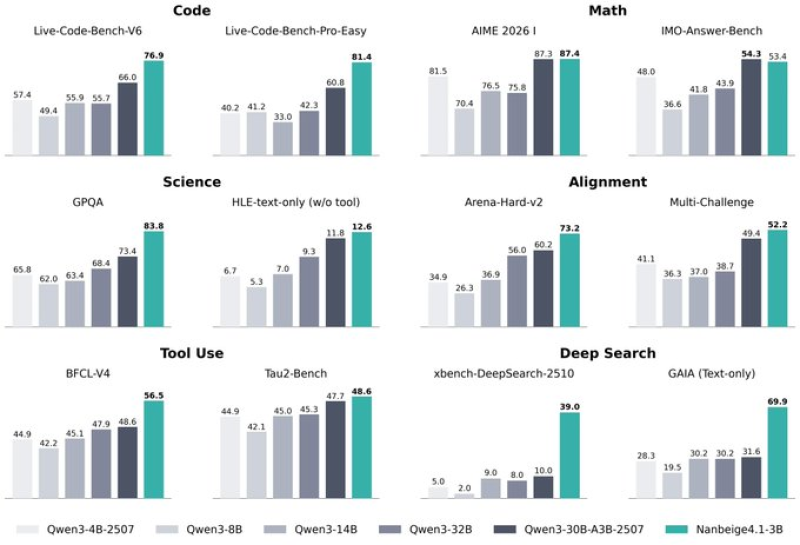
⬤ The secret sauce? Smart training. The team combined supervised fine-tuning with two reinforcement learning phases. First, a point-wise reward model evaluated multiple outputs for each prompt. Then a pair-wise comparison stage refined response quality and cut down on malformed answers. This release proves that smaller models can deliver heavyweight performance when training is done right—you don't always need massive parameter counts to get results.
 Eseandre Mordi
Eseandre Mordi


