 Peter Smith
Peter Smith

⬤ Moonshot AI dropped new benchmark numbers for its Kimi K2 Thinking and Kimi K2 Thinking Turbo models, showing serious improvements in complex reasoning tasks. The systems work by switching between structured thinking cycles and repeated tool calls, which helps them tackle long multi-stage problems that need extended logic chains. Moonshot built these as trillion-parameter mixture-of-experts models fine-tuned in INT4 precision so they run well even on budget hardware.
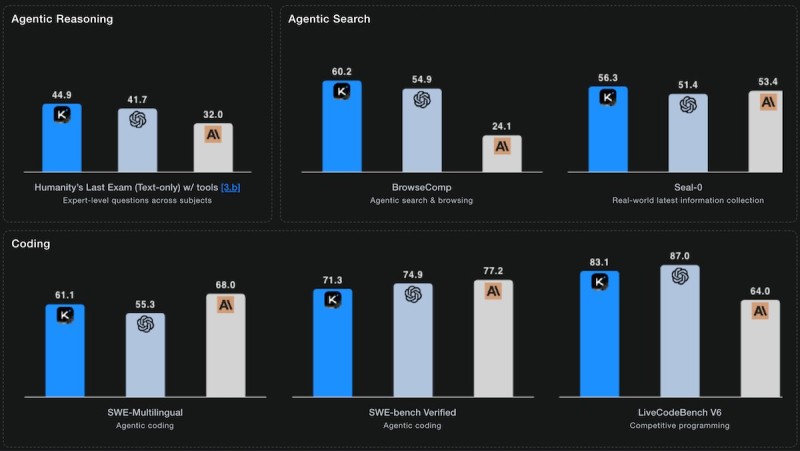
⬤ The benchmark data puts Kimi K2 ahead of other open-weights large language models across several categories like agentic reasoning, search capabilities, and competitive coding. The numbers look strong, with 44.9 on Humanity's Last Exam with tools, 60.2 on BrowseComp for search and browsing tasks, and 56.3 on Seal-0 for real-world information gathering. On coding benchmarks like SWE-Multilingual, SWE-Bench Verified, and LiveCodeBench V6, the Kimi K2 lineup keeps delivering competitive results, showing it can handle different technical challenges without breaking a sweat.
⬤ Moonshot credits the mixture-of-experts architecture for these gains, since it routes tasks between specialized internal components on the fly, boosting reasoning power while keeping computational costs down. The INT4 tuning cuts hardware demands without hurting accuracy. What stands out is that Kimi K2 Thinking Turbo performs consistently well across reasoning, search, and coding tasks, proving it's built for broad capability rather than just gaming one specific benchmark.
⬤ These results point to a bigger trend in AI development, where efficient mixture-of-experts designs are becoming real competitors to massive single models. The strong showing from the Kimi K2 series suggests the market is warming up to cost-effective agentic systems that can handle complicated tasks requiring extended reasoning and heavy tool use.
 Peter Smith
Peter Smith


