 Saad Ullah
Saad Ullah

⬤ Google's Gemini 3 Pro has clinched the top spot on the FrontierMath benchmark, beating out GPT-5.1 and GPT-5 across every difficulty tier. The model scored 38 percent on FrontierMath Tiers 1–3, which test easier to medium-level problems, and hit 19 percent on the brutal Tier 4 challenges. FrontierMath sorts problems by difficulty to see if AI models can actually follow long chains of logical steps without falling apart.
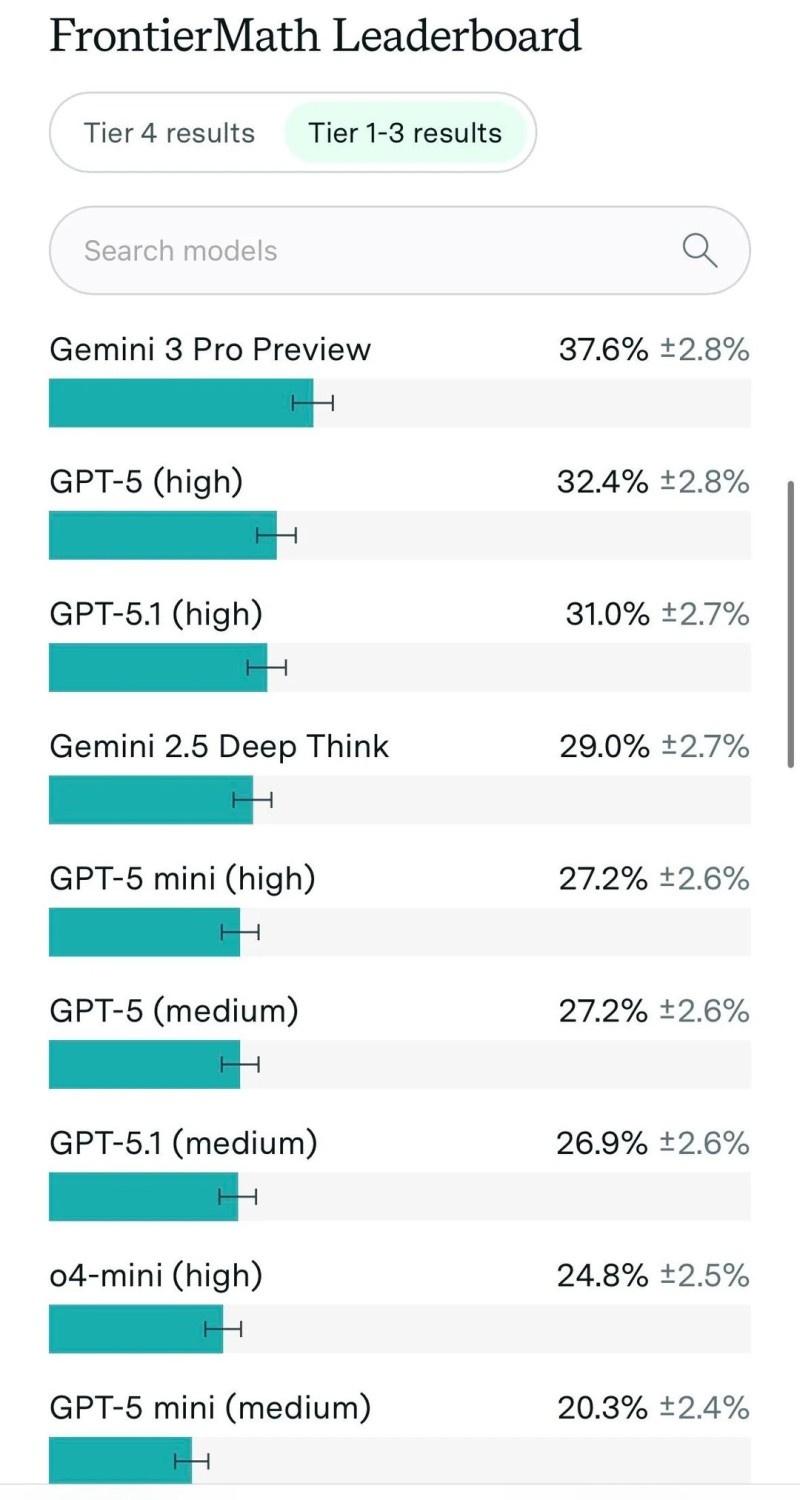
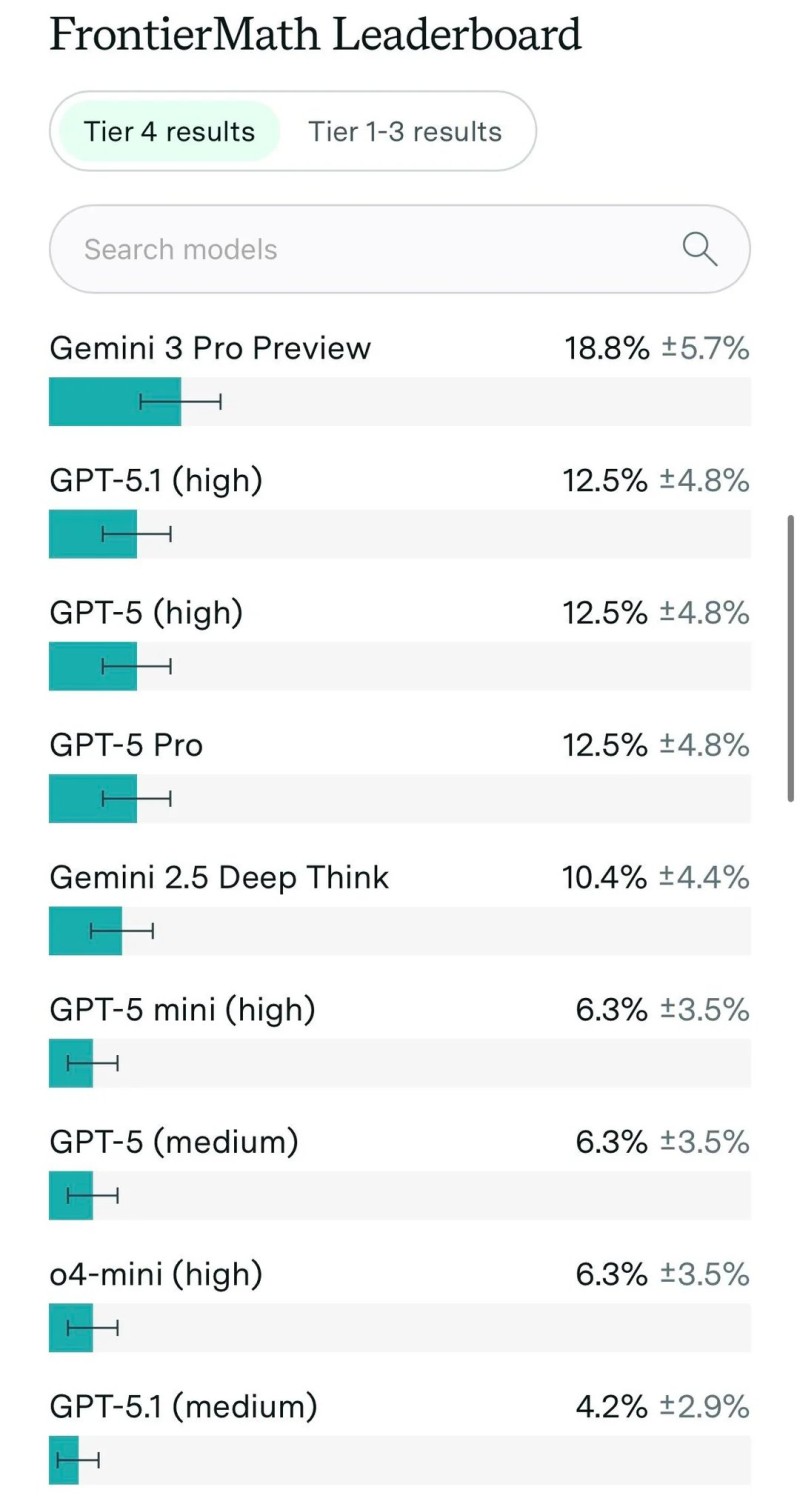
⬤ The leaderboards show Gemini 3 Pro dominating Tier 1–3 with 37.6 percent accuracy, leaving GPT-5 at 32.4 percent and GPT-5.1 at 31.0 percent in the dust. On Tier 4, Gemini 3 Pro reaches 18.8 percent accuracy—way ahead of both GPT-5.1 and GPT-5, which are stuck at 12.5 percent. Getting nearly one in five of these nightmare-level problems right is actually impressive, since they demand the kind of multi-stage planning you'd expect from seasoned mathematicians.
⬤ The Epoch Capabilities Index, which rolls together scores for reasoning, math, coding, and general knowledge, gives Gemini 3 Pro a rating of 154 versus GPT-5.1's 151. That means Google's model isn't just crushing math—it's slightly stronger across the board. The data shows Gemini 3 Pro holding up well in every tested setup, proving these gains aren't a fluke.
⬤ These results put GOOGL's Gemini 3 Pro at the front of the pack in today's cutthroat AI race. FrontierMath is known as one of the toughest tests for mathematical reasoning out there, so the strong showing suggests Google keeps pushing forward in areas that need deep logic and multi-step calculations. The gap on display here could shift expectations around AI leadership, model scaling, and the battle between Google and OpenAI for dominance in high-end reasoning tasks.
 Saad Ullah
Saad Ullah


