 Saad Ullah
Saad Ullah

Alibaba Group's (BABA) Qwen AI team just dropped its Qwen 3.5 Medium Model Series, and the numbers are turning heads. The lineup includes Qwen3.5-Flash, Qwen3.5-35B-A3B, Qwen3.5-122B-A10B, and Qwen3.5-27B, each built around a simple but compelling idea: more intelligence, less compute. As Qwen's previous 80B model showed with its 1M token context window, the team has been on a steady trajectory of architectural efficiency gains rather than just throwing more parameters at problems.
Scores That Matter: 90 in Math, Mid-80s in Graduate Reasoning
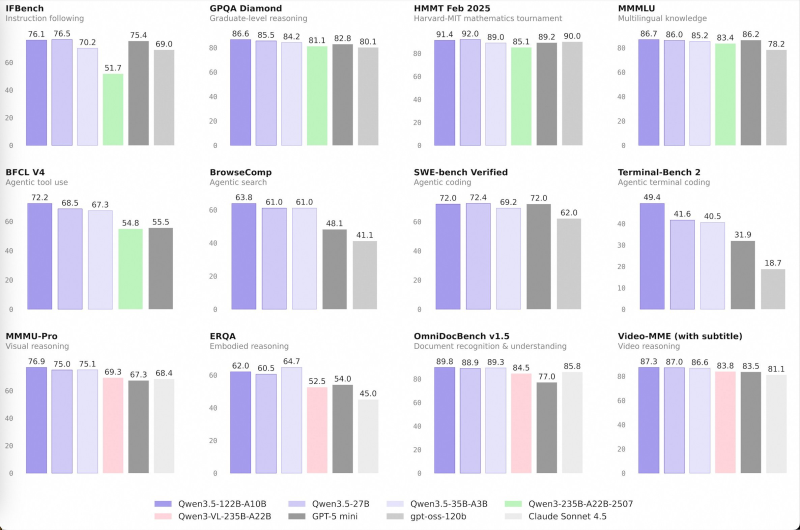
The benchmark results speak for themselves. On GPQA Diamond, a graduate-level science reasoning test, Qwen 3.5 variants landed in the mid-80s. The HMMT Feb 2025 mathematics evaluation saw scores climb above 90. Multilingual knowledge benchmarks like MMLU also held steady in the mid-80 range, while coding and agentic tool-use evaluations showed consistent performance throughout. These aren't small models punching above their weight by a little - they're genuinely competing with some of the biggest names in the space.
Multimodal and Agentic Capabilities Round Out a Versatile Series
The story doesn't stop at text. Qwen 3.5 models posted high marks on OmniDocBench for document understanding and performed well on Video-MME subtitled benchmarks for video reasoning. Alibaba's AI momentum has been building - the company's stock jumped 3% when Qwen AI beta launched and promptly crashed from overwhelming user traffic. Now, with strong visual, agentic search, and embodied reasoning scores, the Qwen 3.5 series positions itself as a genuinely broad-capability platform, not just a text model with a few add-ons.
Amazing benchmark evals" with the philosophy of "more intelligence, less compute.
For businesses evaluating AI deployments, this matters. Alibaba has already integrated Qwen into its revamped Quark AI browser for 100 million users, signaling that these models aren't lab experiments - they're being built for real-world scale. The Qwen 3.5 release reflects a wider industry shift: smarter training methods and leaner architectures are increasingly outpacing the raw compute arms race, giving enterprises more options to balance performance, cost, and capability.
 Saad Ullah
Saad Ullah


