 Usman Salis
Usman Salis

⬤ Qwen just dropped Qwen3-Next-80B-A3B-Thinking, a large-scale AI model built to handle seriously long contexts and complex reasoning tasks. The model is now live on Hugging Face and brings together some notable architectural improvements - specifically combining Hybrid Attention with high-sparsity Mixture of Experts (MoE) to deliver better efficiency and stronger performance on challenging benchmarks.
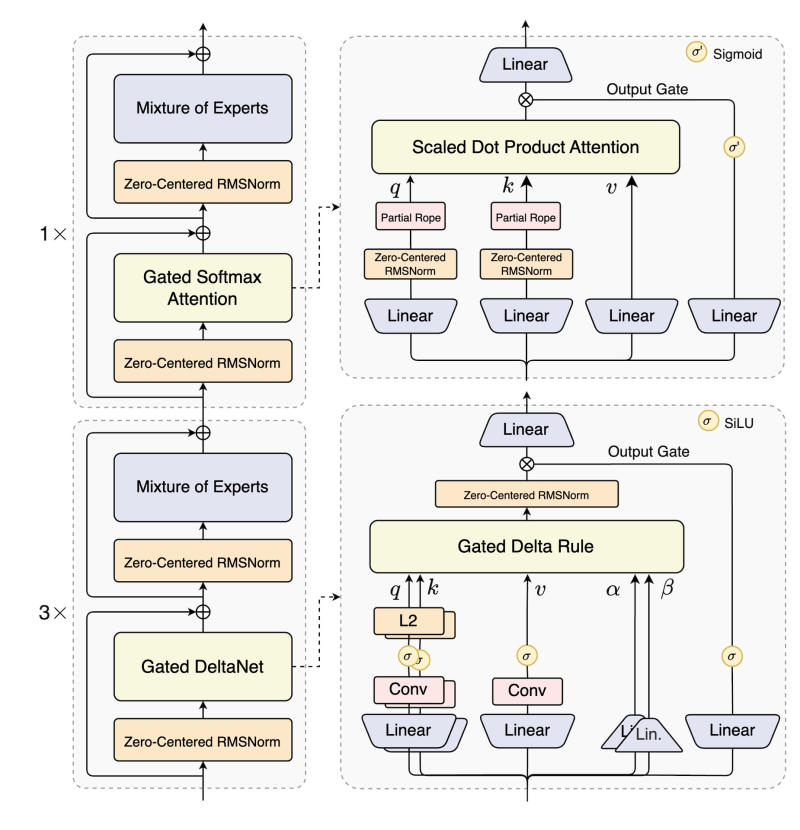
⬤ The standout feature here is the 1 million-token context window, which blows past what most LLMs can handle. Under the hood, the architecture uses Zero-Centered RMSNorm, Gated Softmax Attention, and MoE layers that work together to keep computation efficient without sacrificing accuracy. According to Qwen, this setup lets the model outperform Gemini-2.5-Flash-Thinking on key reasoning benchmarks, showing real gains in both speed and precision thanks to the Hybrid Attention approach.
⬤ The system also incorporates Gated DeltaNet and the Gated Delta Rule, mixing convolutional operations with linear modules and adaptive gating to optimize how information flows through extremely long sequences. The high-sparsity MoE design is particularly clever - it only activates a small fraction of parameters during inference, which dramatically cuts down on compute costs. This means Qwen3-Next-80B-A3B-Thinking can tackle sophisticated multi-step reasoning without the heavy resource demands you'd typically see with dense attention models.

⬤ This release signals where the industry is heading with long-context and reasoning-focused AI. As models push toward million-token inputs and more advanced logical capabilities, Qwen's latest system shows that scalable, efficient, and highly capable architectures are becoming the new standard.
 Usman Salis
Usman Salis


