 Eseandre Mordi
Eseandre Mordi

Artificial intelligence has gotten really good at predicting what might happen next. Show an AI a video, and it can imagine plausible future frames with stunning visual quality. But here's the catch: just because something looks realistic doesn't mean it's useful. Researchers from Tsinghua University and Zhejiang Lab just proved this with WorldArena, a new testing framework that asks a simple but crucial question - can your AI's imagination actually help a robot get things done? This disconnect between appearance and capability echoes broader concerns about how AI assistance shapes coding skills in practical applications.
Why Visual Realism Doesn't Equal Practical Intelligence
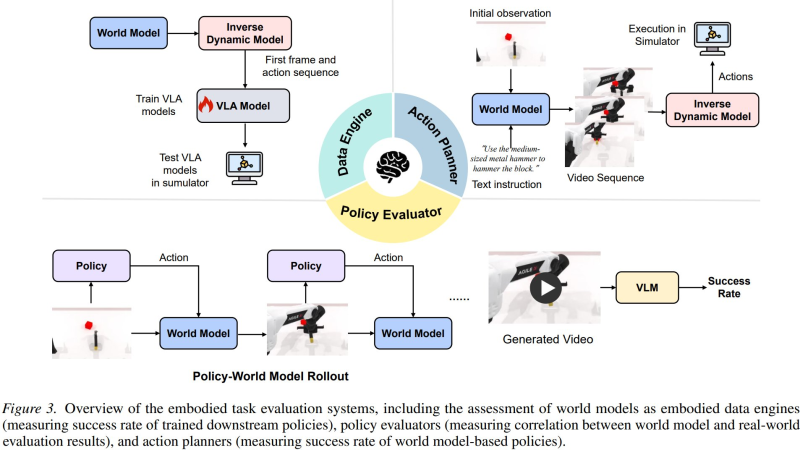
The team created WorldArena specifically to bridge the gap between perception and action. Traditional AI benchmarks have focused almost entirely on how realistic generated videos look. WorldArena flips the script by measuring functional utility - whether those predicted future states actually help an AI agent complete tasks in simulated environments.
The results? Eye-opening. Models producing Hollywood-quality video predictions consistently bombed at planning and control tasks. This disconnect isn't just academic. We're seeing similar patterns across the industry, from Toyota Canada brings in Agility Robotics' Digit for factory automation to real-world deployment challenges.
How WorldArena Actually Works
The benchmark connects three critical components into one evaluation pipeline. First, a world model predicts future frames based on current observations. Then an inverse dynamics model figures out what actions would be needed to reach those predicted states. Finally, a policy evaluator measures whether the AI can actually succeed at embodied tasks using those predictions.
What makes this different from older benchmarks? WorldArena uses vision-language models to assess real task success rates, not just pixel-perfect accuracy. It's testing whether your AI can help a robot navigate a warehouse or assemble components - not whether it can fool a human judge in a video quality contest.
The Imagination Gap in Autonomous Systems
The empirical findings reveal a troubling pattern. High visual fidelity and functional performance don't correlate the way many researchers assumed. Some of the most photorealistic world models produced the worst planning outcomes. This challenges fundamental assumptions about how we're developing autonomous systems.
These capability gaps extend beyond robotics. Issues like AI agents can do the work but can't share it highlight similar disconnects between impressive demos and practical deployment. WorldArena's unified scoring system - combining perception and functional metrics - offers a more honest assessment of what AI can actually do versus what it appears capable of doing.
 Eseandre Mordi
Eseandre Mordi


