 Eseandre Mordi
Eseandre Mordi

⬤ Google DeepMind's Titans architecture just crushed the long-context challenge, hitting 70% recall and reasoning accuracy at ten million tokens on the BABILong benchmark. The performance chart puts Titans head-to-head with models like Qwen2.5-72B, GOT4o-mini, GPT-4, Mamba-FT, and RMT-FT—and Titans stays way ahead as sequence lengths stretch. The key difference? Continual learning baked directly into the architecture, letting Titans maintain accuracy where others collapse.
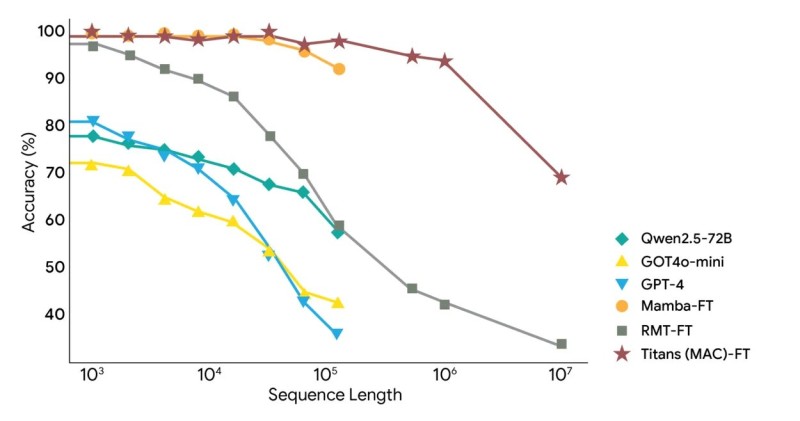
⬤ The numbers tell a clear story. GPT-4 starts strong near 80% but slides below 60% once you push past 100,000 tokens. GOT4o-mini and Qwen2.5-72B follow the same pattern, dropping into the 40–60% range as contexts expand. RMT-FT takes an even harder hit, falling under 30% at maximum length. Titans? It holds near 100% accuracy through early sequences and still delivers 70% at ten million tokens. That continual learning framework keeps it sharp while competitors fade.
⬤ This shift matters for the AI ecosystem. Long-context capability is becoming the new battleground as use cases demand more—think massive document analysis, multi-step reasoning chains, scientific research workloads, and conversations that actually remember what happened five pages ago. Titans' consistent performance across millions of tokens marks a real jump from current architectures. Market watchers are already recalculating expectations around compute requirements, infrastructure scaling, and competitive timelines for next-gen models.

⬤ Why this benchmark result carries weight: long-context strength is separating leaders from followers in AI development. When one model stays reliable at extreme lengths while others break down, it opens doors for new applications and forces the industry to rethink what's possible. Titans shows that stability at scale isn't just theoretical—it's here. That means fresh questions about capability limits, deployment strategies, and where AI performance is heading next.
 Eseandre Mordi
Eseandre Mordi


