 Eseandre Mordi
Eseandre Mordi

⬤ Teams from Generative AI Labs and collaborating institutions just published findings that challenge a widespread AI practice: persona prompting doesn't actually make systems more accurate. Models were put through GPQA Diamond and MMLU-Pro tests to see if telling an AI "you are a physics expert" produces better answers on tough factual questions. Turns out, it doesn't.
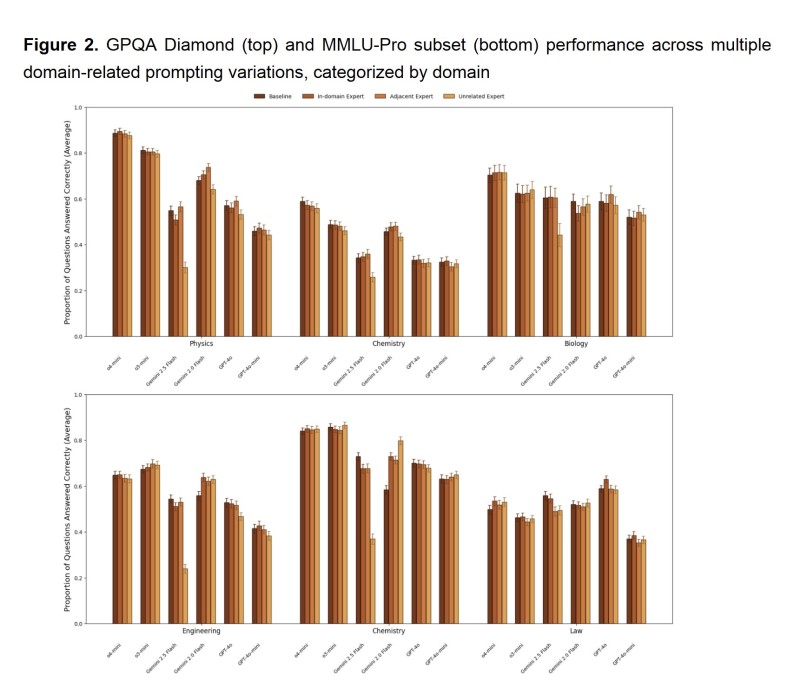
⬤ The numbers tell a clear story—persona assignments made almost no difference across physics, chemistry, biology, engineering, and law. Bar charts from the research show in-domain expert personas performing nearly identically to basic prompts, with only tiny variations between models. Even mismatched personas, like giving a legal identity to science problems, didn't hurt or help performance in any meaningful way. The only consistent pattern? Low-knowledge personas such as toddler or layperson roles dropped accuracy, which matches what researchers saw in controlled tests.

⬤ Four prompting styles were tested: baseline, in-domain expert, adjacent expert, and unrelated expert. Across both GPQA Diamond and MMLU-Pro, accuracy scores clustered tight together with no clear winner. The takeaway is straightforward—personas might change how an AI sounds, but they don't make it reason better or get facts right.

⬤ This finding points to something bigger happening in AI development: real accuracy gains will come from better model design, stronger training data, and smarter evaluation methods—not clever prompt tricks. As more companies lean on AI for serious analytical work, studies like this could reshape how teams build prompts and where they invest to make systems more reliable.
 Eseandre Mordi
Eseandre Mordi


