 Marina Lyubimova
Marina Lyubimova

⬤ Fresh academic work shows that ordering an AI system to “pretend to be an expert” does not raise its factual accuracy. Researchers fed the models prompts like “you are a top physicist” or “you are a lawyer” and ran the test across multiple large language models. The answers did not become more correct, although the wording sounded different. The experiment covered three kinds of personas - experts who belong to the topic, experts from unrelated fields plus personas that claimed little knowledge. The questions came from hard benchmarks in advanced science, engineering and law.

⬤ The outcome was plain. Expert personas did not lift the score on hard questions. Prompts that cast the model as an in domain expert matched the baseline. Off-domain expert roles gave no gain. Low-knowledge roles dragged the score down.
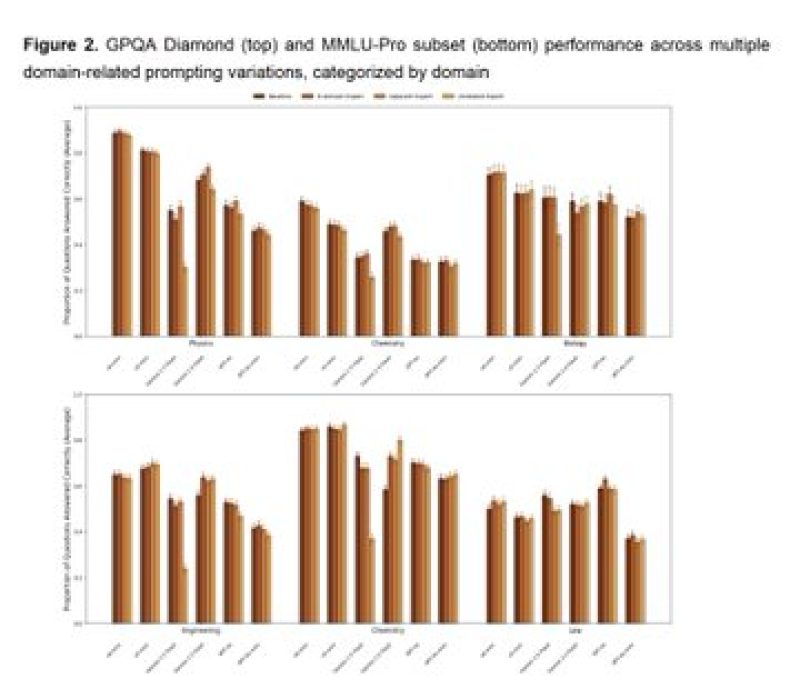
⬤ The finding carries weight while firms like Apple weave AI deeper into consumer devices and professional tools. Models now appear in enterprise suites as well as everyday applications, but the study shows that accuracy rises through stronger training and better model design, not through clever wording.

⬤ For the technology industry the lesson is plain - genuine progress in AI rests on technical advance, not on surface tricks. As companies lean on those systems for critical work knowing what truly raises reliability will steer competitive plans or adoption paths ahead.
 Marina Lyubimova
Marina Lyubimova


