 Peter Smith
Peter Smith

⬤ Zhipu AI just dropped RealVideo, a real-time conversational video system that creates animated responses straight from text prompts. The model is now live on Hugging Face, giving developers a new tool for building AI-generated characters and interactive digital assistants. This puts Zhipu AI right in the mix with other companies building multimodal AI that combines text, audio, and video into dynamic outputs.
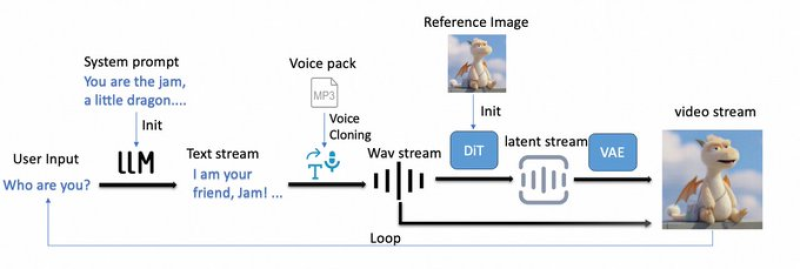
⬤ RealVideo works as a streaming system that connects an LLM text generator with voice synthesis and video production. The process starts with the LLM creating a text response, which instantly converts into cloned voice audio. That audio feeds into a DiT model that shapes the visual stream, then a VAE decoder produces the final real-time video. "The system supports character initialization through a reference image, enabling consistent identity and lip-sync throughout the interaction," according to the technical documentation.
⬤ Being able to generate continuous, synced video in real time is a big step up from older batch-processed video models. RealVideo runs as a looped streaming engine where each text input triggers new speech and video frames. It's built for conversational uses like AI companions, digital presenters, virtual call agents, and interactive media tools.

⬤ RealVideo's launch comes as major AI companies race to deliver more immersive multimodal systems that blend video, audio, and natural language at scale. For investors, this signals the rapid growth of real-time generative media—a sector that could drive future demand for compute infrastructure and AI-driven applications. Zhipu AI's partnership with Hugging Face also shows how open access models continue to shape adoption trends across the AI ecosystem.
 Peter Smith
Peter Smith


