 Saad Ullah
Saad Ullah

⬤ Qwen3-VL has claimed the top spot in the 8B model category based on fresh benchmark results. The latest Qwen3-VL 8B Instruct variant shows clear improvements over the initial Qwen3 8B release, posting higher scores in knowledge, reasoning, multilingual tasks, and instruction following. What makes this particularly notable is that these gains came with roughly 75% fewer training FLOPs compared to earlier Qwen3 models.
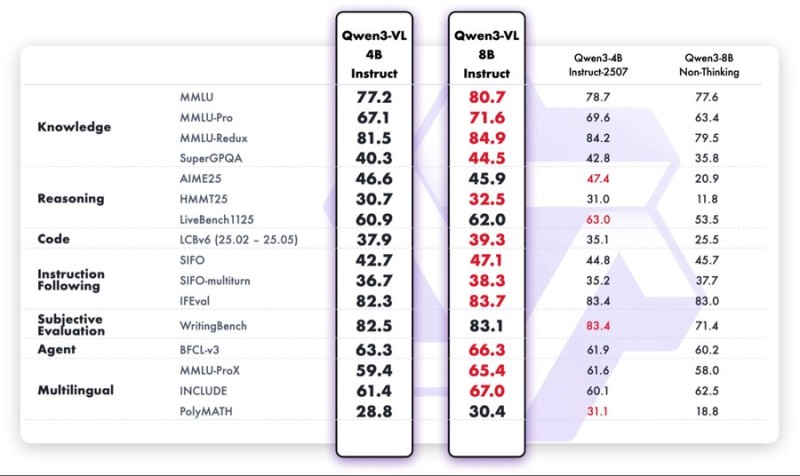
⬤ Benchmark tables reveal Qwen3-VL 8B leading across several categories, including BFCL v3, the only directly comparable metric across test groups. Other measurements like MMLU-Redux, SIFO, and WritingBench also show meaningful jumps. When stacked against competitors like RnJ-1 Instruct, Llama 3.1 8B, Gemma 3 12B, and Codetral 12B Instruct, Qwen3-VL holds its ground or tops the charts in areas such as HumanEval+, MBPP, and BigCodeBench.
⬤ The compute budget differences are striking. RnJ-1 Instruct was trained on 417 zettaFLOPs, while earlier Qwen3 models required substantially higher volumes. Yet Qwen3-VL delivers stronger results across intelligence, coding, and reasoning benchmarks. This gap highlights how training methodology and dataset quality are becoming more critical than raw compute power.
⬤ Qwen3-VL's success as a leading 8B architecture could reshape how organizations think about model deployment. Getting better performance with fewer resources will likely push companies to rethink their approach to model size, costs, and practical implementation strategies across the LLM landscape.
 Saad Ullah
Saad Ullah


