 Saad Ullah
Saad Ullah

● Qwen unveiled two new multimodal AI models, Qwen3-VL-2B and Qwen3-VL-32B, calling them "dense powerhouses" built for high performance per GPU. The 32B version beats GPT-5 Mini and Claude 4 Sonnet across STEM, visual QA, OCR, video comprehension, and agent tasks.

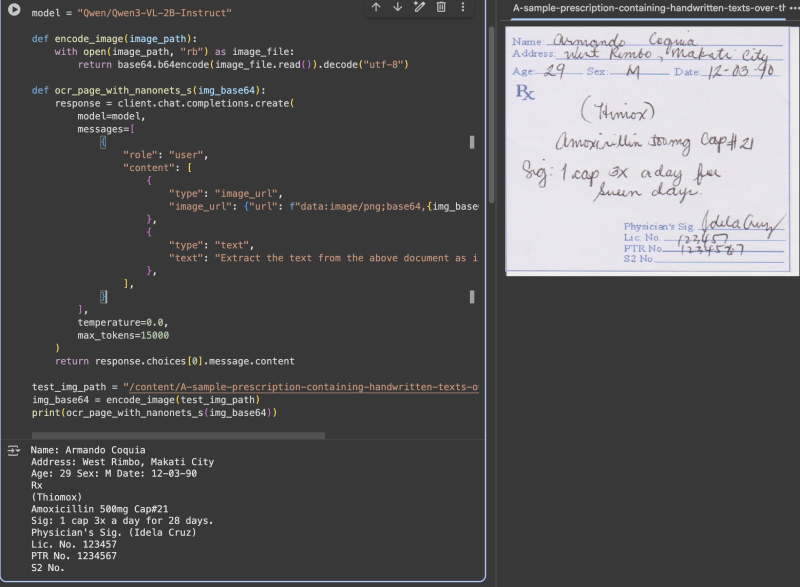
● AI researcher Maziyar Panahi highlighted the 2B model's surprising strength at reading messy handwriting, noting it handled a doctor's prescription with ease—something many larger systems fail at. He wrote: "For its size, DAMN!"
● The Qwen3-VL lineup includes "Instruct" and "Thinking" modes, letting developers pick between quick responses or deeper reasoning without needing huge, expensive models. However, experts warn that smaller dense architectures still face challenges like staying aligned, avoiding hallucinations, and running smoothly on low-memory hardware.
● FP8 precision cuts compute costs sharply, making these models practical for industries like healthcare, robotics, and document automation. The 2B model runs on-device, offering a cheaper alternative to cloud-locked services like GPT-5 Mini or Claude 4 Sonnet.
● Benchmarks show Qwen3-VL-32B hitting 85.9 on OCR accuracy and outscoring even 200B-parameter models on tests like OSWorld and DeepBench. @Qwen says the releases "pack full Qwen3-VL capabilities into compact, scalable forms."
● By blending efficiency with sharp reasoning, Alibaba's Qwen3-VL family stakes a serious claim in the multimodal AI race, raising the bar for performance, clarity, and deployment options.
 Saad Ullah
Saad Ullah


