 Marina Lyubimova
Marina Lyubimova

OpenAI's GPT-5.4 has posted strong results on the latest WeirdML benchmark evaluation, landing a 77.7% average accuracy score across all 19 tasks in the suite. The model places just behind GPT-5.3 Codex and Claude Opus 4.6, though the gap falls within the statistical margin of error. WeirdML tests machine learning models on tasks requiring reasoning, code generation, and iterative improvement - making it one of the more demanding public benchmarks available today.
WeirdML v2 Expands to 19 Tasks Across 8 AI Labs
The new version of WeirdML more than triples the original benchmark scope, now covering 19 tasks versus the previous six. Beyond accuracy, it also tracks API cost, token usage, code length, and execution time - giving a much clearer picture of what it actually costs to run these models at scale. GPT-5.4, models from Anthropic, Google, Meta, DeepSeek, xAI, Mistral, and Qwen all appear across the leaderboard at different accuracy and cost tiers.
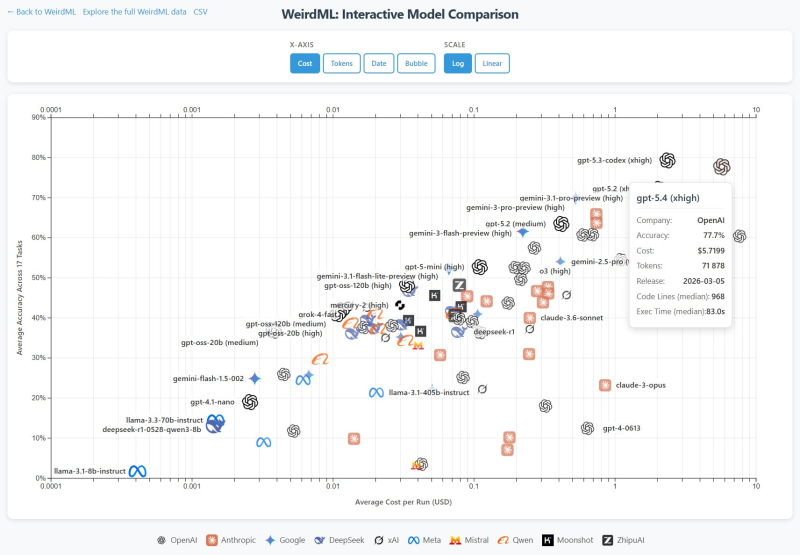
One figure that stands out immediately is GPT-5.4's token consumption. The model averages around 72,000 tokens per run, frequently pushing against the 128,000-token context limit. That translates into costs comparable to Claude Opus 4.6 - despite similar performance levels.

The code output gap is even more striking: GPT-5.4 produces a median of roughly 968 lines per solution, while Claude Opus 4.6 typically generates around 169 lines for the same tasks.
Cost vs. Performance: A Wide Pareto Frontier
The cost-versus-performance chart from the benchmark reveals a wide Pareto frontier - multiple models from different companies dominate different cost segments without a single clear winner across the board.
The pattern confirms that raw benchmark scores are no longer the only metric that matters. Efficiency, token footprint, and cost per run are increasingly central to how models are evaluated in real deployment scenarios. These dynamics are explored further in the GPT-5 Shadow API study revealing 47% performance gaps, which examines how new architectures and deployment choices are reshaping the competitive landscape.
 Marina Lyubimova
Marina Lyubimova


