 Usman Salis
Usman Salis

⬤ A new benchmark puts Nemotron 3 Super at the top of AI output speed rankings, reaching roughly 484 tokens per second - ahead of dozens of models from competing providers. The chart compares output speed across APIs and architectures, making inference efficiency the key variable. As developers push for real-time responsiveness, optimization at the architecture level is becoming just as critical as raw model size. NVIDIA's broader Nemotron push has been covered in NVIDIA launches Nemotron 3 Nano 30B - a 3.3x speed boost in a compact model.
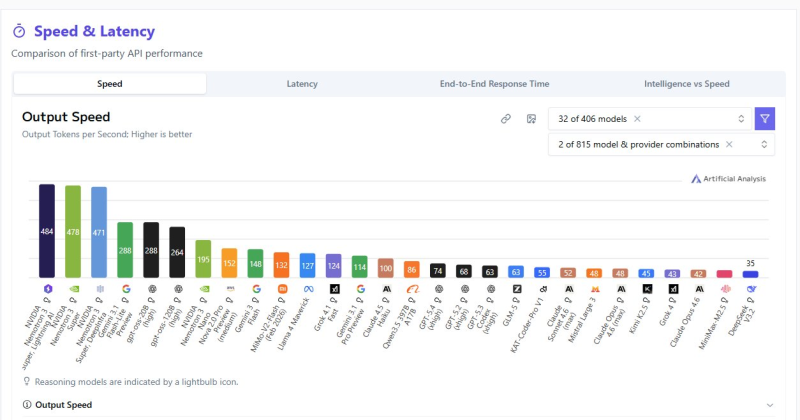
⬤ Other top contenders in the benchmark cluster around 478 and 471 tokens per second, while many systems lag far behind at 288, 264, or even 195 tokens per second. That gap matters in production. Conversational AI, coding assistants, and enterprise automation all depend on near-instant output. Infrastructure choices - memory bandwidth, batching strategies, hardware pairing - explain much of that spread. The role of memory architecture in these gains is explored in AI agent memory: the 4-layer infrastructure driving next-gen systems.
⬤ Nemotron 3 Super's speed comes from multi-token prediction - generating several tokens at once rather than one at a time. The first token is accepted immediately; the rest stay provisional. On the next inference pass, the model checks those tokens and keeps them if correct. If not, one token is still accepted, keeping the autoregressive process intact. The result is higher throughput with minimal extra cost - GPUs at small batch sizes have headroom to spare.
⬤ Multi-token prediction is part of a wider shift where architectural choices drive performance as much as scale. Faster generation cuts latency across real-time applications and improves efficiency at scale. Other teams are exploring different angles - better training data and smarter scaling strategies, as seen in Qwen-34B matches models 50x larger using a 9,225-problem Chimera dataset.
 Usman Salis
Usman Salis


