 Eseandre Mordi
Eseandre Mordi

As Artificial Analysis reported, Google has released Gemini 3.1 Flash Live Preview, a speech-to-speech AI model that achieved a 95.9% score on the Big Bench Audio benchmark at its highest reasoning setting. The result places it second overall, behind Step-Audio R1.1 Realtime at 97.0%. The release introduces configurable thinking levels, letting developers adjust reasoning depth and latency as GOOGL continues expanding its AI ecosystem alongside developments like GPT-5.4 mini scores 72.1 on OSWorld.
The model's highest thinking level delivers near-peak intelligence performance, while switching to minimal reduces the score to 70.5%.
Gemini 3.1 Flash Outperforms Grok and Other Speech AI Rivals
Benchmark results confirm Gemini 3.1 Flash Live Preview outperforms competitors including Grok Voice Agent, which scored 92.9%, placing Google firmly among top-tier speech reasoning models.
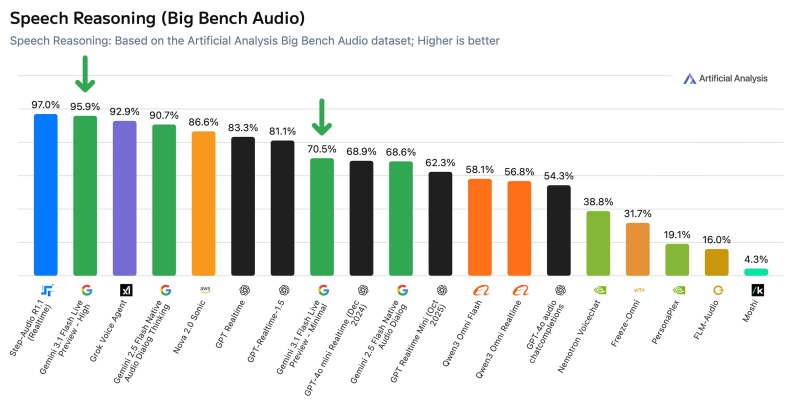
The drop in accuracy at lower thinking settings corresponds with a significant improvement in speed, illustrating a clear trade-off between reasoning depth and latency. These capabilities align with broader advancements in AI reasoning systems such as Google DeepMind's Aletheia hits 91.9 on math benchmark.
Gemini 3.1 Flash Latency Drops to 0.96 Seconds on Minimal Thinking
Latency metrics further highlight the model's flexibility. At the highest reasoning level, Time to First Audio (TTFA) sits at approximately 2.98 seconds, slower than Step-Audio R1.1 Realtime at 1.51 seconds and Grok Voice Agent at 0.78 seconds. However, when configured to minimal thinking, TTFA drops to 0.96 seconds, approaching faster systems while maintaining competitive performance. Pricing stays at $0.35 per hour for audio input and $1.38 per hour for audio output, consistent with previous Gemini audio models. The balance between speed and intelligence reflects a broader trend seen in NanoClaw AI launches Claude-powered assistant.
Pricing remains unchanged at $0.35 per hour for audio input and $1.38 per hour for audio output.
The release highlights a shift toward customizable AI performance, where developers can dynamically balance latency and reasoning depending on application requirements. As GOOGL advances its position in real-time voice AI, features like adjustable thinking levels may influence deployment strategies across industries relying on speech interfaces.
- Gemini 3.1 Flash Live Preview scores 95.9% on Big Bench Audio benchmark
- Highest thinking level: TTFA of 2.98 seconds; minimal thinking: 0.96 seconds
- Grok Voice Agent scored 92.9%; Step-Audio R1.1 Realtime leads at 97.0%
- Pricing: $0.35/hr audio input, $1.38/hr audio output
This evolution underscores increasing competition in multimodal AI, where performance, responsiveness, and cost efficiency are becoming central to adoption and long-term market positioning.
 Eseandre Mordi
Eseandre Mordi


