 Marina Lyubimova
Marina Lyubimova

The latest round of AI benchmark results reveals a clear split at the top of the market. OpenAI's compact GPT-5.4 Mini is pulling ahead in real-world execution tasks, while Google's Gemini 3 Flash dominates reasoning evaluations. Rather than one model winning across the board, the data points to a landscape where different architectures excel in fundamentally different ways.
GPT-5.4 Mini Leads Execution Tasks With 60% on Terminal-Bench 2.0
GPT-5.4 Mini posts some of the most competitive scores in applied AI benchmarks: 54.4% on SWE-Bench Pro, 60.0% on Terminal-Bench 2.0, and 72.1% on OSWorld-Verified. These categories test how well a model handles software engineering tasks, terminal interactions, and OS-level operations. By those metrics, OpenAI's smaller model clearly outperforms Anthropic's Claude Haiku 4.5, which scores 50.7% on OSWorld-Verified and 34.6% on MCP Atlas compared to GPT-5.4 Mini's 57.7%.
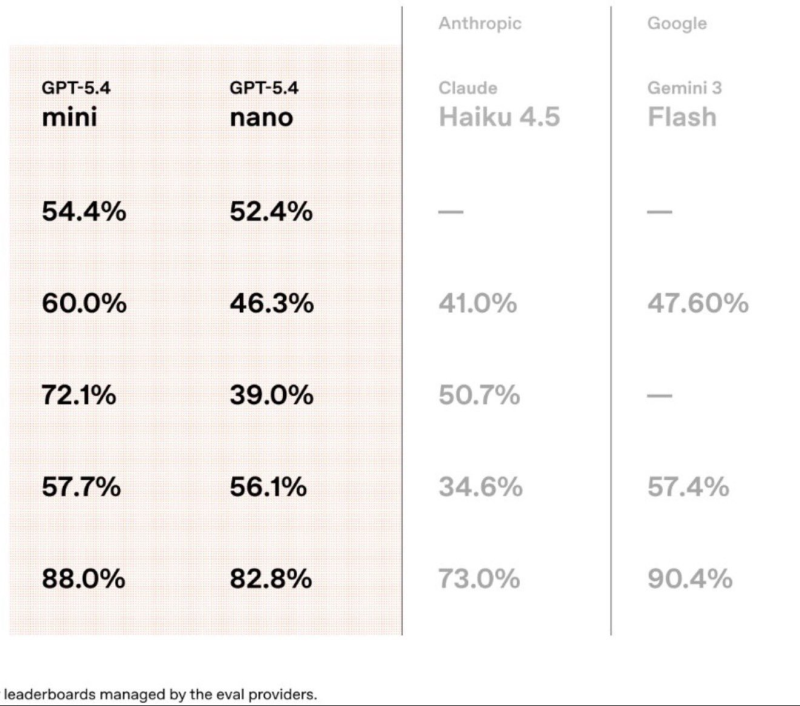
Gemini 3 Flash Reaches 90.4% GPQA Diamond - Highest in the Comparison
Google's Gemini 3 Flash achieves 90.4% on GPQA Diamond - the highest figure across all models evaluated - showing strong non-code reasoning when context is well structured. The result aligns with Google's broader strategy of pushing reasoning and multimodal capabilities across its Gemini lineup. Notably, Gemini 3 Flash does not appear in SWE-Bench Pro results, limiting direct comparison in software engineering tasks.
GPT-5.4 Nano also deserves a mention: the lightest model in OpenAI's lineup still manages 52.4% on SWE-Bench Pro and 82.8% on GPQA Diamond - numbers that would have been considered strong for much larger models just a year ago. As Google advances its Gemini embedding stack and OpenAI refines its compact models, the competitive gap between reasoning accuracy and real-world execution is becoming the defining axis of AI development in 2025.
 Marina Lyubimova
Marina Lyubimova


