 Victoria Bazir
Victoria Bazir

⬤ Google DeepMind just dropped new results for its Gemini Deep Think research system and its internal powerhouse, Aletheia. According to Chubby, the model scored close to 90% on the brutal IMO-ProofBench Advanced benchmark and handled math problems that would've stumped earlier chatbots cold.
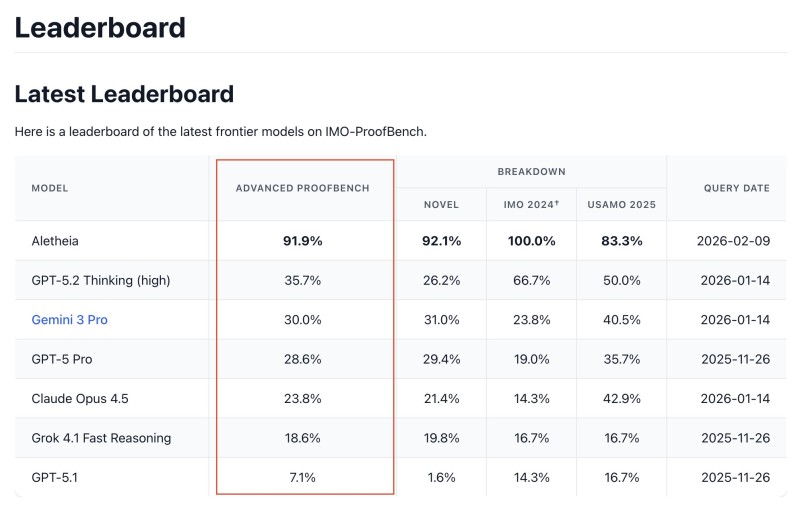
⬤ The leaderboard tells the whole story: Aletheia crushed it with 91.9% on Advanced ProofBench. Meanwhile, GPT-5.2 Thinking managed just 35.7%, Gemini 3 Pro hit 30.0%, GPT-5 Pro came in at 28.6%, Claude Opus 4.5 scored 23.8%, Grok 4.1 Fast Reasoning landed at 18.6%, and GPT-5.1 barely scraped 7.1%. Human experts graded these results, revealing a massive performance gap when it comes to Olympic-level reasoning challenges.
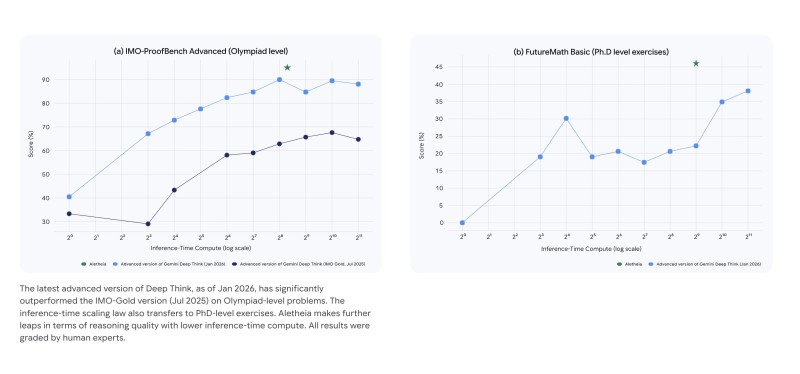
⬤ The charts show something even more interesting: the reasoning improvements grow with more compute power and stretch all the way to PhD-level exercises. We're not just talking about better chatbot answers here. This is about structured reasoning and verification that actually holds up under scrutiny. As one researcher noted,
The model was described as solving open mathematics problems and contributing to research work across algorithms, economics, machine learning optimization, and theoretical physics topics.
⬤ These results signal where AI development is heading next. The jump in reasoning accuracy and verification processes opens doors for scientific and technical work that demands real precision. As research-focused AI keeps evolving, we're seeing systems that can genuinely assist with complex analytical workflows rather than just spit out plausible-sounding text. Read more about Google DeepMind's research.
 Victoria Bazir
Victoria Bazir


