 Saad Ullah
Saad Ullah

⬤ A performance showdown across leading AI coding systems exposed a gap between benchmark rankings and real production capability in the software ecosystem tied to companies like Nvidia. Bridge Bench's real-world coding test evaluated Claude Opus 4.6, GPT-5.2 Codex, and GLM-5 using actual programming tasks instead of synthetic metrics.
⬤ Claude Opus 4.6 hit a score of 60.1 with an average 8.3-second response time, while GPT-5.2 Codex landed at 58.3 with 19.9 seconds. GLM-5 managed just 41.5 and needed 156.7 seconds on average. Task completion told an even sharper story: Claude finished all 130 tasks, GPT-5.2 Codex completed 129 out of 130, and GLM-5 wrapped only about 75 out of 130. GLM-5's broader benchmark positioning had previously placed it among leading models in rankings.
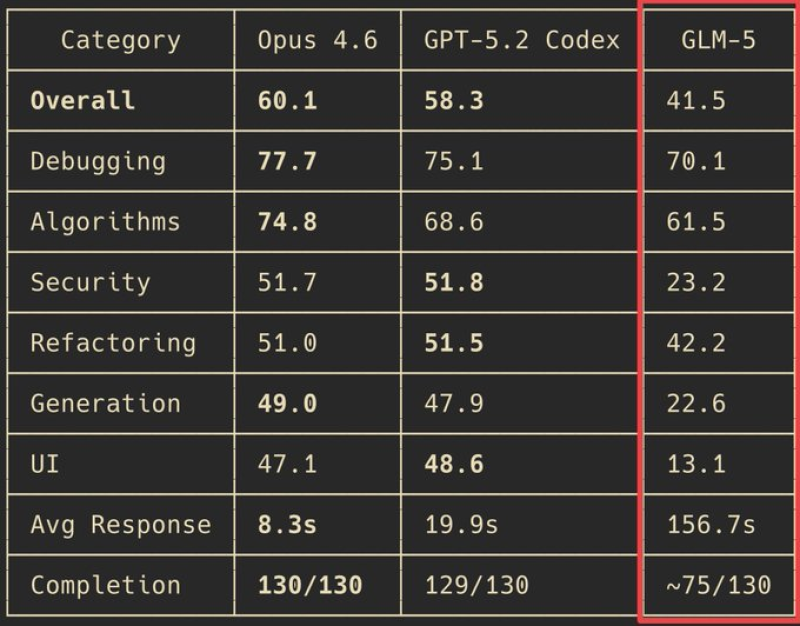
⬤ Category-level results showed GLM-5 trailing across debugging, algorithms, security, refactoring, generation, and UI tasks. While leaderboard-style tests hinted at parity with top models, hands-on workflow testing revealed consistent gaps. Similar competitive dynamics among open models have been discussed in coverage of opensource AI model rivals.
⬤ The comparison shows how practical workflow testing can diverge from leaderboard benchmarks. Operational reliability, response time, and completion rates increasingly determine the usability of coding AI systems as development teams evaluate tools for consistent production integration.
 Saad Ullah
Saad Ullah


