 Eseandre Mordi
Eseandre Mordi

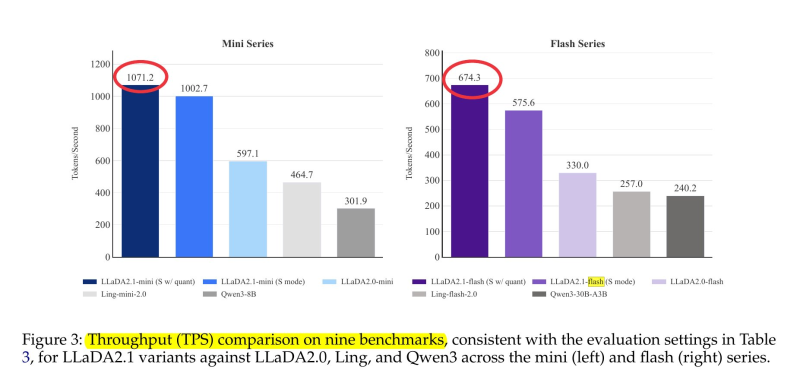
⬤ Rohan Paul shared news that Ant Open Source dropped LLaDA2.1 Flash, a large language diffusion mixture-of-experts model built for serious inference speed. The system clocked a peak throughput of 892 tokens per second using a generation approach that breaks away from the old-school sequential decoding method.
⬤ Rather than spitting out text one token at a time, this thing drafts multiple token positions at once. It throws together a rough draft first, then immediately fixes any mistakes as soon as more context rolls in. This "draft then edit" setup means the model can catch and correct early errors instead of baking them into the final text.
The model combines parallel drafting, token editing, and adjustable decoding behavior within a single generation process designed to increase text generation throughput while maintaining output consistency.
⬤ Benchmark tests show LLaDA2.1 Flash crushing the throughput of the smaller Qwen3-30B-A3B model by roughly 2.5×. The architecture packs configurable decoding modes too—a speed-focused mode drafts faster and leans on edits, while a quality-focused mode slows down the drafting to cut down on corrections.
⬤ The model blends parallel drafting, token editing, and adjustable decoding into one generation process that's laser-focused on pumping up text generation throughput without sacrificing output quality.
Read more about LLaDA2.1 Flash and how it compares to traditional language models in production environments.
 Eseandre Mordi
Eseandre Mordi


