 Usman Salis
Usman Salis

⬤ Alibaba launched Qwen3-VL, its latest multimodal model that brings significant upgrades to vision-language AI. The system features a native 256K context window for both text and video, allowing it to handle longer sequences and more sophisticated multimodal tasks. This release represents the company's most advanced vision-language system yet, positioning Alibaba more prominently in the competitive AI landscape.
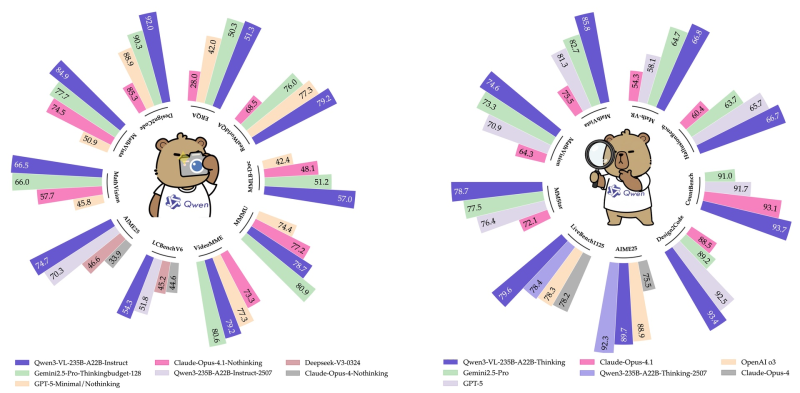
⬤ Performance data shows Qwen3-VL leading across numerous benchmarks including MathVision, AIME25, VideoMME, MMStar, MMBench-Doc, Design2Code, and LiveBench1125. The model demonstrates clear improvements in visual understanding, structured reasoning, and task handling compared to previous versions, consistently ranking at the top of performance charts across multiple evaluation categories.
⬤ The model excels in complex tasks requiring mathematical reasoning, code generation from images, document analysis, and multi-step visual question answering. Its combination of extended context handling and stronger perception makes it suitable for research applications, enterprise automation, technical analysis, and advanced multimodal assistant development.
⬤ Qwen3-VL's release highlights the intensifying competition in multimodal AI, where context length, reasoning precision, and cross-domain flexibility have become critical factors. Alibaba's strong benchmark results reinforce its position in the global race for vision-language leadership, while setting new standards that may shape future expectations for AI model capabilities and real-world deployment across various industries.
 Usman Salis
Usman Salis


