 Eseandre Mordi
Eseandre Mordi

⬤ Z AI's GLM-4.7-Flash (Reasoning) just grabbed the crown as the smartest open-weights model under 100B parameters. The Artificial Analysis Intelligence Index v4.0 gave it a score of 30—better than anything else in its weight class. Here's the kicker: it's only running 31B total parameters with 3B active at any given time. That's some serious efficiency engineering right there.
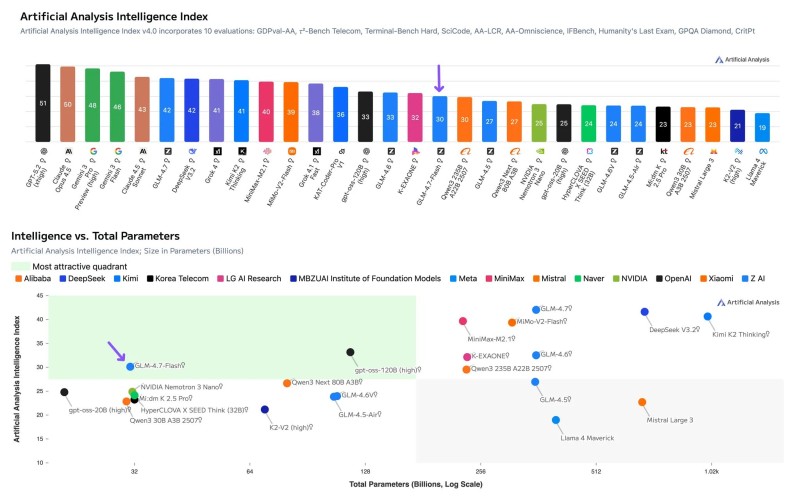
⬤ The official Artificial Analysis chart shows GLM-4.7-Flash sitting pretty at the 30-point mark, leaving competitors in the dust. It outperformed Qwen3 Next 80B A3B, gpt-oss-20B (high), HyperCLOVA X SEED Think 32B, and Qwen3 30B A3B 2507. Sure, the bigger GLM-4.7 (Reasoning) scored 42 points, but that's a totally different beast running at way larger scale. The gap between these two versions shows just how much optimization matters.
⬤ The benchmark breakdown tells an interesting story. GLM-4.7-Flash crushed it on the Artificial Analysis Agentic Index with a score of 46 and an 887 ELO on GDPval-AA—the highest agentic performance of any model below 100B parameters. It also nailed roughly 99% on τ²-Bench Telecom, beating every other system tested. But it's not all perfect. Knowledge-heavy tasks? Not so much. The Omniscience Index showed weaker results compared to similar-sized models, and CritPt only gave it 0.3%, putting it behind some rivals while matching others.

⬤ Why does this matter? Because smaller models are getting scary good at reasoning tasks without needing massive compute budgets. GLM-4.7-Flash proves you don't need hundreds of billions of parameters to compete on intelligence scores. For developers and companies looking at deployment costs, this is huge. It's also a reminder that benchmarks like the Artificial Analysis Intelligence Index are becoming critical for figuring out which models actually deliver in real-world scenarios across the AI landscape.
 Eseandre Mordi
Eseandre Mordi


