 Alex Dudov
Alex Dudov

⬤ Think3D represents a major step forward in how AI models handle spatial understanding. Instead of analyzing flat images, this framework reconstructs full 3D scenes from visual inputs, allowing models to actually "see" depth, position, and spatial relationships the way humans do. The system converts standard visual data into interactive 3D representations that support precise object placement and relational analysis.
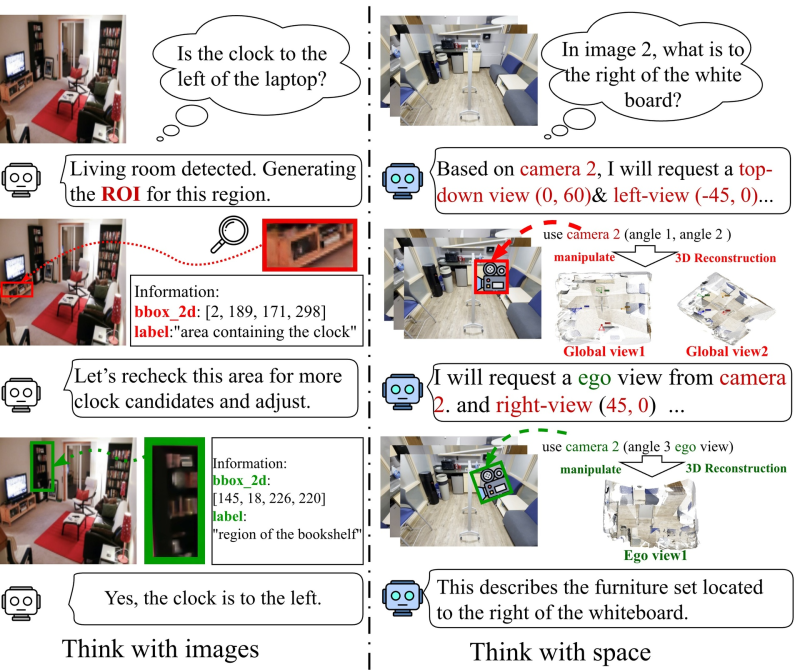
⬤ The framework works by merging information from multiple camera angles into one cohesive 3D environment. When the model encounters spatial ambiguity, it can request different viewpoints—overhead shots, side angles, or first-person perspectives—to clarify object positions and relationships. This creates an interactive reasoning process where the AI verifies spatial information through 3D exploration rather than guessing from limited 2D data.
⬤ Testing showed Think3D delivers a 7.8% accuracy boost on spatial reasoning tasks when used with GPT-4.1 and Gemini 2.5 Pro. What makes this particularly impressive is that these gains come purely from better spatial understanding—no additional training, fine-tuning, or computational overhead required. The framework simply helps existing models use spatial information more effectively.

⬤ Think3D points toward the future of multimodal AI development, where system-level improvements unlock new capabilities without expanding model size. For robotics, embodied AI systems, and digital assistants operating in physical spaces, this kind of spatial reasoning becomes essential. The framework shows how smarter reasoning architectures can extend what AI can do while making its decision-making more transparent and reliable in real-world environments.
 Alex Dudov
Alex Dudov


