 Eseandre Mordi
Eseandre Mordi

⬤ Vision-Language-Action models are quickly becoming central to embodied AI research, bridging the gap between seeing, understanding language, and taking action in the real world. These systems process visual data, interpret spoken or written commands, and execute physical tasks—all within one integrated framework.
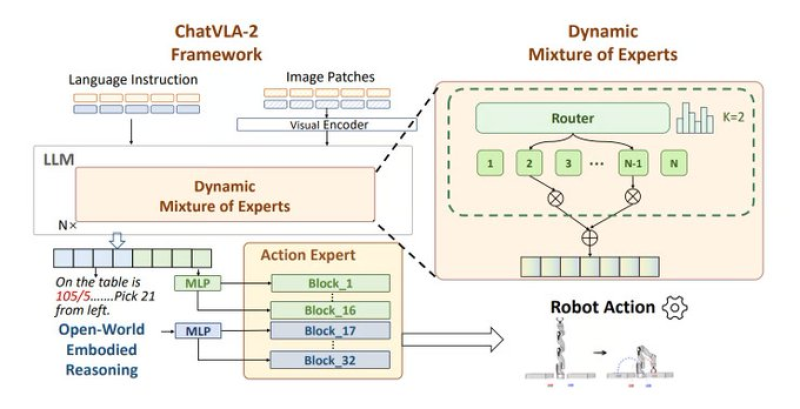
⬤ The overview spotlights eight models pushing this field forward: Gemini Robotics, π0, SmolVLA, Helix, ChatVLA-2, ACoT-VLA, VLA-0, and Rho-alpha. ChatVLA-2 stands out with its Mixture-of-Experts design, where language prompts and image data flow through a visual encoder before being dynamically routed to specialized expert modules. The system then generates action outputs based on which experts handle each specific task.
⬤ Microsoft's Rho-alpha represents the latest entry from a major tech player diving into embodied AI. The list also includes compact solutions like SmolVLA and reasoning-focused systems such as ACoT-VLA, which uses action-level chain-of-thought processing to break down complex tasks.
⬤ This collection matters because it shows how teams are testing different strategies to merge vision, language, and action into cohesive systems. As these models continue evolving, they're set to influence robotics, automation, and interactive AI applications across industries.
 Eseandre Mordi
Eseandre Mordi


