 Eseandre Mordi
Eseandre Mordi

⬤ Tencent AI Lab launched R-Few, a training framework that helps large language models teach themselves with barely any human help. The approach brings in a Challenger–Solver architecture designed to fix common problems in iterative LLM development—things like diversity collapse, concept drift, and wobbly self-training cycles. The framework uses two complementary processes working together to sharpen model performance in a structured way.
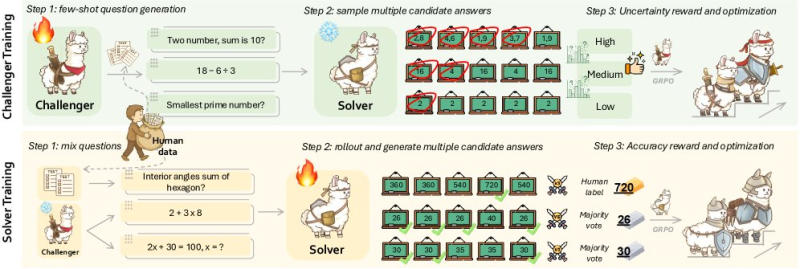
⬤ In the Challenger training pipeline, the Challenger creates few-shot questions and hands them to the Solver, which responds with multiple possible answers. An uncertainty-based reward system then grades these answers, sorting them into high-, medium-, and low-confidence groups. This reward setup fine-tunes the Solver step by step, pushing answer quality higher while keeping drift in check and maintaining steady behavior across training rounds.
⬤ During Solver training, the system mixes human-written questions with ones the Challenger came up with. The Solver generates multiple candidate answers again, but this time they're judged through accuracy rewards based on either human labels or majority-vote results. This feedback loop ties model improvements to verified information instead of letting the system reinforce its own mistakes. The two reward systems—uncertainty and accuracy—work as a tag team to keep the model's self-evolution stable and trustworthy.

⬤ Tencent's R-Few represents a growing trend toward scalable, low-supervision training methods as LLMs get more sophisticated. By letting models generate their own training data, evaluate their uncertainty, and ground improvements in validated outputs, R-Few opens a door to more budget-friendly and robust AI development. With rising interest in autonomous and continuously learning AI systems across both research labs and industry, frameworks like R-Few could become essential building blocks for next-generation language technologies.
 Eseandre Mordi
Eseandre Mordi


