 Eseandre Mordi
Eseandre Mordi

⬤ India's AI startup Sarvam AI has released two new open-weight reasoning models, Sarvam 30B and Sarvam 105B, expanding the country's footprint in the global large language model space. The release builds on the company's earlier milestone documented in Sarvam AI releases 105B model with 98.6 Math500 score and full open-source stack, underscoring the steady technical momentum behind the Sarvam AI ecosystem.
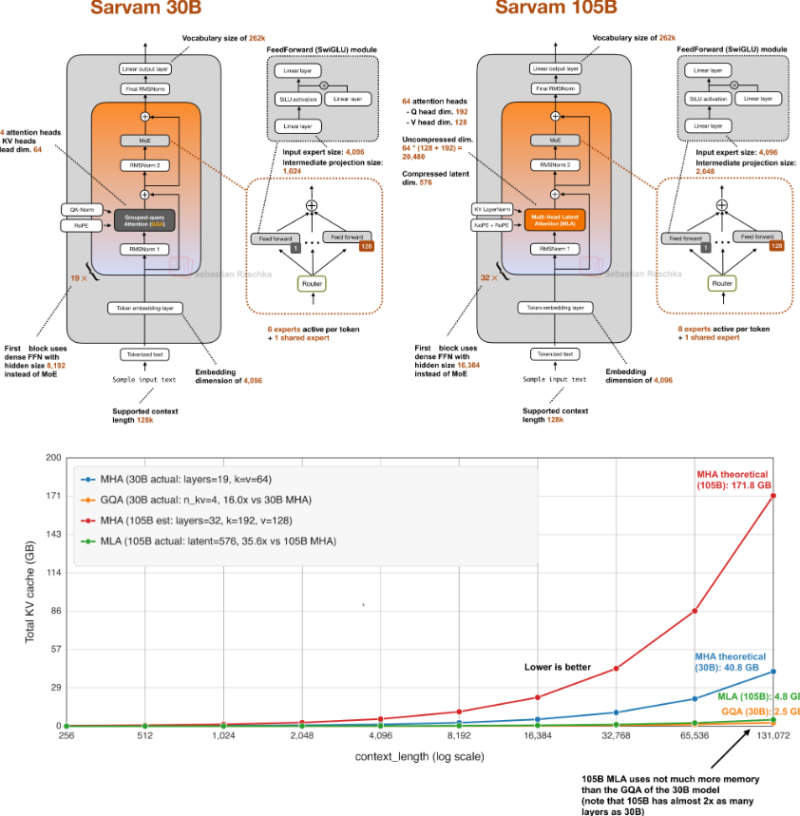
⬤ The smaller Sarvam 30B runs on Grouped Query Attention (GQA), a widely adopted mechanism that cuts memory consumption during inference by sharing key and value projections across multiple query heads. This shrinks KV-cache size and keeps things efficient over long context windows, letting the model hold its own on reasoning tasks without demanding excessive compute.
The models differ in their attention architecture while sharing a similar reasoning-focused design.
⬤ The larger Sarvam 105B takes a different route with Multi-Head Latent Attention (MLA), an architecture drawn from DeepSeek research. MLA compresses key-value data into a latent space, cutting memory overhead as context length grows. Benchmarks suggest the 105B performs on par with comparable large models, with strong numbers on reasoning and task-completion evaluations. For context, the benchmark landscape keeps shifting, as seen in how GLM-5 trails by 18.6 points in real-world AI coding benchmarks.
⬤ Both models are built with multilingual use in mind, specifically for Indian languages. Sarvam developed a custom tokenizer tuned to regional language patterns, boosting token efficiency and accuracy across multilingual inputs. The company's broader ecosystem is also pushing into hardware and consumer AI, as shown in Sarvam AI smart glasses challenging Meta and Google with 10-language support, pointing to an integrated technology buildout well beyond just foundational models.
 Eseandre Mordi
Eseandre Mordi


