 Usman Salis
Usman Salis

Indian AI startup Sarvam AI just made a bold move in the open-source AI race, releasing two reasoning models built entirely on in-house infrastructure. With benchmark numbers that rival established global players, Sarvam-105B is a signal that high-performance AI development is no longer concentrated in Silicon Valley. The company's approach to multilingual and full-stack AI development is already drawing attention across the industry.
Sarvam-105B Posts 98.6 on Math500 Alongside Strong Coding and Knowledge Scores
Sarvam AI has open-sourced both Sarvam-30B and Sarvam-105B, positioning the pair as globally competitive open models. According to a recent post on X, the models are built on a full-stack approach that includes proprietary data pipelines, training infrastructure, reinforcement learning workflows, tokenizer design, and inference optimization. The goal is to produce AI systems that can run efficiently across high-end GPUs and consumer-grade hardware alike.
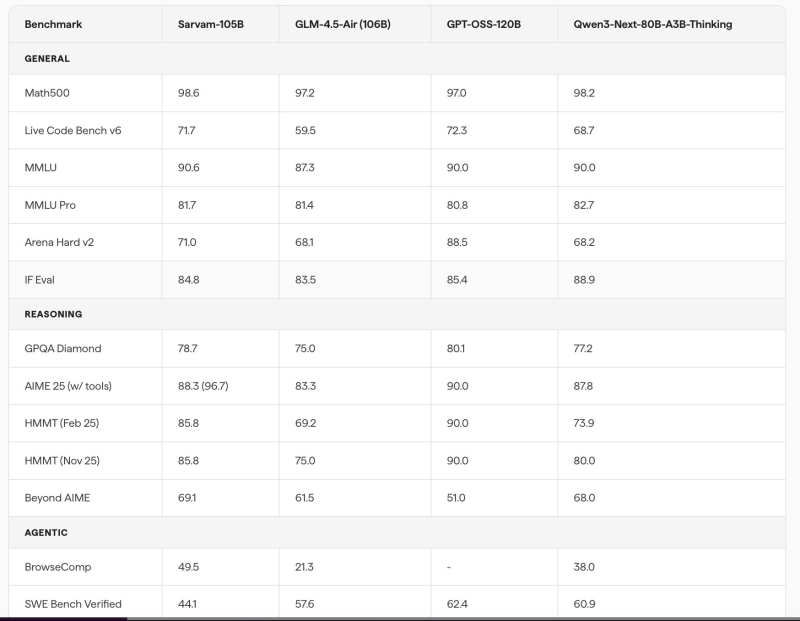
Benchmark results for Sarvam-105B tell an impressive story. The model achieves 98.6 on Math500, placing it among the top performers in that category. It also scores 71.7 on Live Code Bench v6, 90.6 on MMLU, and 81.7 on MMLU Pro, showing competitive strength in both coding and general knowledge tasks.
By building models using internally developed data pipelines and training infrastructure, Sarvam AI aims to create systems capable of handling complex reasoning and multilingual workloads.
On Arena Hard v2, the model lands at 71.0, while IF Eval reaches 84.8, reflecting solid instruction-following across demanding prompts.
Sarvam-105B Reaches 88.3 on AIME 2025 in Advanced Reasoning and Agentic Tests
On advanced reasoning benchmarks, Sarvam-105B scores 78.7 on GPQA Diamond, 88.3 on AIME 2025 with tools, and 85.8 on HMMT, reflecting strong multi-step reasoning in math and science. The model also reaches 69.1 on Beyond AIME, a benchmark built for deeper reasoning chains. For those tracking how benchmark performance translates into real-world capability, recent analysis of OpenAI vs. Anthropic's Feb-27 benchmark spike offers useful context on how these numbers actually stack up.
In agentic evaluations, Sarvam-105B achieves 49.5 on BrowseComp and 44.1 on SWE Bench Verified, demonstrating real capability in web browsing tasks and software engineering workflows. These scores show a model designed not just for benchmarks, but for practical deployment in complex, multi-step environments.
The release of both models marks a meaningful moment for open-source AI beyond the traditional tech hubs. By owning every layer of the stack, from data collection to inference, Sarvam AI is showing how regional players can build globally relevant models. As interest in medical and specialized AI applications grows, broader ecosystem efforts like Google's nationwide study on medical AI signal just how rapidly open model development is reshaping the industry landscape.
 Usman Salis
Usman Salis


